RAFT——光流估计算法
引言: RAFT(Recurrent All-Pairs Field Transforms)是一种用于光流估计的深度网络架构。核心创新包括:(1)全对相关体积:构建所有像素对的 4D 相关体积,同时捕获大位移和小位移;(2)循环更新算子:基于 GRU 的轻量级更新模块,仅 2.7M 参数即可迭代 100+ 次;(3)单分辨率流场:避免粗到细级联的局限性。在 KITTI 上达到 5.10% F1-all 误差(相比最佳结果降低 16%),在 Sintel final pass 上达到 2.855 像素 EPE(降低 30%)。
✈️ RAFT 算法介绍
光流估计是计算机视觉中的经典问题,目标是为视频帧间的每个像素计算运动位移。传统方法将其建模为优化问题,通过数据项(视觉相似性对齐)和正则化项(运动平滑性约束)的权衡来求解。然而,手工设计的优化目标难以处理快速运动物体、遮挡、运动模糊和弱纹理等边缘情况。
深度学习方法直接预测光流,绕过了优化问题的形式化。但现有架构普遍采用「粗到细」设计:先在低分辨率估计大位移,再逐步上采样细化。这种级联结构存在三个关键问题:
- 粗分辨率误差传播:低分辨率阶段的错误难以在后续阶段纠正
- 小物体遗漏:小而快速移动的物体容易被遗漏
- 训练成本高:多阶段级联通常需要超过 1M 次训练迭代
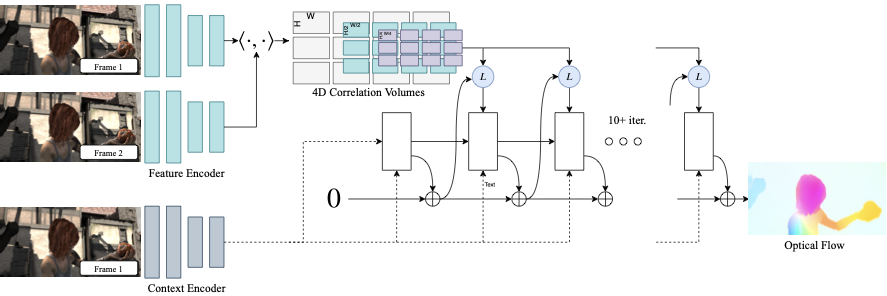
RAFT 采用完全不同的设计思路——维护单一的高分辨率流场,通过循环更新算子迭代优化。受传统优化方法启发,RAFT 将特征提取、视觉相似性计算和迭代更新三个阶段设计为端到端可训练的架构:
核心优势:
- 全对相关体积:对图像间所有像素对计算特征相关性,同时编码大小位移信息
- 循环更新算子:权重共享的 GRU 模块,仅 2.7M 参数即可执行 100+ 次迭代
- 强泛化能力:仅用合成数据训练,在 KITTI 上达到 5.04 像素 EPE,比先前最佳方法降低 40%
🚀 RAFT 算法流程
给定连续两帧 RGB 图像 I1 和 I2,RAFT 估计一个密集位移场 (f1, f2),将 I1 中的每个像素 (u, v) 映射到 I2 中的对应位置 (u + f1(u), v + f2(v))。
算法分为三个阶段:特征提取、视觉相似性计算和迭代更新。
特征提取
特征编码器 gθ 从两帧输入图像中提取密集特征图。编码器将输入图像映射到 1/8 分辨率的特征图:
gθ : ℝH × W × 3 ↦ ℝH/8 × W/8 × D
其中特征维度 D = 256。编码器由 6 个残差块组成:2 个在 1/2 分辨率、2 个在 1/4 分辨率、2 个在 1/8 分辨率。
此外,上下文网络 hθ 仅从第一帧图像 I1 提取特征。上下文网络与特征编码器结构相同,其输出直接注入到更新算子中,提供空间上下文信息。两个网络只需执行一次,后续迭代中复用。
视觉相似性计算
给定图像特征 gθ(I1) ∈ ℝH × W × D 和 gθ(I2) ∈ ℝH × W × D,通过计算所有像素对的内积构建 4D 相关体积:
Cijkl = ∑hgθ(I1)ijh ⋅ gθ(I2)klh
相关体积 C ∈ ℝH × W × H × W 可通过单次矩阵乘法高效计算。
相关金字塔:对相关体积的后两个维度进行池化,构建 4 层金字塔 {C1, C2, C3, C4}。池化核大小分别为 1、2、4、8,因此 Ck 的维度为 H × W × H/2k × W/2k。

金字塔结构捕获不同尺度的位移信息,而保持前两个维度(I1 维度)为高分辨率,使模型能够恢复小而快速运动物体的位移。
相关查找:给定当前光流估计 (f1, f2),将每个像素 x = (u, v) 映射到估计的对应位置 x′ = (u + f1(u), v + f2(v))。定义以 x′ 为中心、半径为 r 的局部网格:
𝒩(x′)r = {x′ + dx | dx ∈ ℤ2, ∥dx∥1 ≤ r}
对金字塔每层 Ck,使用网格 𝒩(x′/2k)r 进行索引。由于网格坐标为实数,采用双线性采样。恒定半径在不同层级意味着更大的感受野——最底层 k = 4 使用半径 4 对应原图 256 像素范围。各层查找结果拼接为单一特征图。
高分辨率高效计算:全对相关复杂度为 O(N2),但只需计算一次且与迭代次数 M 无关。对于高分辨率图像,存在一种 O(NM) 复杂度的等价实现:预计算池化后的特征图,在每次迭代时按需计算相关值。
迭代更新
更新算子从初始流场 f0 = 0 开始,迭代产生更新方向 Δf:
fk + 1 = fk + Δf
更新算子以当前流场、相关特征和隐藏状态为输入,输出流场更新和更新后的隐藏状态。架构设计模拟优化算法的迭代步骤,使用权重共享和有界激活来鼓励收敛到不动点。
初始化:默认将流场初始化为零。对于视频应用,可使用「热启动」初始化:将前一帧对的光流前向投影到当前帧,遮挡区域用最近邻插值填充。
输入:给定当前流场估计 fk,从相关金字塔检索相关特征,通过 2 层卷积处理。同时对流场估计本身应用 2 层卷积生成流特征。最后注入上下文网络的特征。输入特征图为相关、流和上下文特征的拼接。
更新:核心组件是基于 GRU 的门控激活单元,将全连接层替换为卷积:
其中 xt 是流、相关和上下文特征的拼接。还实验了可分离 ConvGRU:用两个 GRU 替代 3 × 3 卷积——一个使用 1 × 5 卷积,另一个使用 5 × 1 卷积,在不显著增加模型大小的情况下扩大感受野。
流预测:GRU 输出的隐藏状态通过两层卷积预测流更新 Δf。输出流场为 1/8 分辨率。
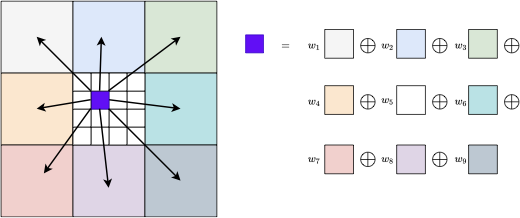
上采样:网络输出 1/8 分辨率的光流,需要上采样到全分辨率。采用可学习的上采样:将全分辨率光流定义为 3×3 粗分辨率邻域的凸组合。使用两层卷积预测 H/8 × W/8 × (8 × 8 × 9) 的掩码,对 9 个邻域权重进行 softmax 归一化。最终光流通过加权组合、置换和重塑得到 H × W × 2 维流场。
监督信号
对完整预测序列 {f1, ..., fN} 使用指数增长的权重监督 L1 损失:
其中 γ = 0.8。这种加权策略鼓励后期迭代产生更准确的预测。
🎯 训练细节与实验结果
实现细节
RAFT 使用 PyTorch 实现,所有模块从头随机初始化。训练使用 AdamW 优化器,梯度裁剪到 [−1, 1] 范围。评估时,Sintel 使用 32 次更新迭代,KITTI 使用 24 次。每次更新 Δf + fk,仅通过 Δf 分支反向传播梯度,fk 分支梯度置零。
训练流程: - FlyingChairs 预训练 100k 迭代,batch size 12 - FlyingThings3D 训练 100k 迭代,batch size 6 - Sintel 微调 100k 迭代(混合 Sintel、KITTI-2015、HD1K 数据) - KITTI-2015 额外微调 50k 迭代
Sintel 基准
| 训练数据 | 方法 | Sintel Clean | Sintel Final | KITTI F1-all |
|---|---|---|---|---|
| C+T | FlowNet2 | 2.02 | 3.54 | 30.0 |
| C+T | PWC-Net | 2.55 | 3.93 | 33.7 |
| C+T | VCN | 2.21 | 3.68 | 25.1 |
| C+T | RAFT | 1.43 | 2.71 | 17.4 |
| C+T+S+K+H | MaskFlowNet | - | - | 6.10 |
| C+T+S+K+H | VCN | 2.81 | 4.40 | 6.30 |
| C+T+S+K+H | RAFT (2-view) | 1.94 | 3.18 | 5.10 |
| C+T+S+K+H | RAFT (warm-start) | 1.61 | 2.86 | - |
Sintel SOTA:RAFT 在 Sintel clean pass 达到 1.61 像素 EPE,在 final pass 达到 2.86 像素,分别超越先前最佳方法 36% 和 30%。仅用 C+T 训练时,泛化性能也大幅领先:Sintel clean 达到 1.43 像素,比 FlowNet2 降低 29%。
KITTI 基准
在 KITTI-2015 测试集上,RAFT 达到 5.10% F1-all 误差,在所有光流方法中排名第一。仅用合成数据训练时,RAFT 在 KITTI 训练集上达到 5.04 像素 EPE,比先前最佳方法 VCN(8.36 像素)降低 40%。
消融分析
| 组件 | Sintel Clean | Sintel Final | KITTI F1-all | 参数量 |
|---|---|---|---|---|
| ConvGRU vs Conv | 1.63 vs 2.04 | 2.83 vs 3.21 | 19.8 vs 26.1 | 4.8M vs 4.1M |
| 权重共享 vs 独立 | 1.63 vs 1.96 | 2.83 vs 3.20 | 19.8 vs 24.1 | 4.8M vs 32.5M |
| 有无上下文 | 1.63 vs 1.93 | 2.83 vs 3.06 | 19.8 vs 23.1 | 4.8M vs 3.3M |
| 单尺度 vs 多尺度特征 | 1.63 vs 2.08 | 2.83 vs 3.12 | 19.8 vs 23.2 | 4.8M vs 6.6M |
| 查找半径 (0/1/2/4) | 3.41/1.80/1.78/1.63 | - | - | - |
| 相关池化 (无/有) | 1.95 vs 1.63 | 3.02 vs 2.83 | 23.2 vs 19.8 | - |
| 相关范围 (32/64/128/全对) | 2.91/2.06/1.64/1.63 | - | - | - |
| 相关 vs 扭曲 | 1.63 vs 2.27 | 2.83 vs 3.73 | 19.8 vs 32.1 | 4.8M vs 2.8M |
关键设计验证:ConvGRU 的门控机制帮助流估计序列收敛;权重共享显著减少参数量且提升精度;全对相关优于局部搜索和扭曲特征;相关池化捕获多尺度位移信息。
效率分析
| 方法 | 参数量 | 推理时间 (10 iter) | 训练迭代数 |
|---|---|---|---|
| FlowNet2 | 38M | - | - |
| PWC-Net | 8.7M | - | - |
| VCN | 6.2M | - | - |
| RAFT | 5.3M | 102ms | 200k |
| RAFT-S | 1.0M | - | - |
RAFT 在参数效率、推理时间和训练迭代数三个维度均优于先前方法。RAFT-S 仅 1M 参数(PWC-Net 和 VCN 的 1/6),仍在 Sintel clean pass 上超越它们。
推理迭代数影响:
| 迭代数 | Sintel Clean | Sintel Final | KITTI F1-all |
|---|---|---|---|
| 1 | 4.04 | 5.45 | 44.5 |
| 3 | 2.14 | 3.52 | 29.9 |
| 8 | 1.61 | 2.88 | 19.6 |
| 32 | 1.43 | 2.71 | 17.4 |
| 100 | 1.41 | 2.72 | 17.4 |
| 200 | 1.40 | 2.73 | 17.4 |
迭代 3 次即超越 PWC-Net,迭代 6 次超越 FlowNet2。模型在 32 次迭代后趋于收敛,且在 200 次极端迭代下不发散。
💡 洞察与结论
单分辨率优于粗到细级联:RAFT 在高分辨率流场上直接迭代更新,避免了粗到细设计的三个局限——粗分辨率误差传播、小物体遗漏和大量训练迭代。全对相关体积确保每次更新都能访问大小位移信息。
循环更新即学习优化:更新算子模拟一阶优化算法的迭代步骤,但梯度方向通过网络学习而非手工定义。权重共享约束搜索空间、减少过拟合风险、加速训练并提升泛化。
迭代精度可控:推理时可自由选择迭代次数,实现精度-效率权衡。迭代 3 次即超越 PWC-Net,迭代 32 次达到 SOTA。
热启动扩展到视频:由于单分辨率设计,可以将前一帧光流投影作为当前帧初始化。这在粗到细架构中难以实现,因为每层金字塔的初始化需要不同处理。
局限与未来方向: 1. 高分辨率计算开销:全对相关体积 O(N2) 复杂度,对于 1080p 视频,相关计算占 17% 推理时间 2. 遮挡处理:当前方法未显式建模遮挡,在遮挡边界可能产生误差 3. 实时性:550ms/帧(1080p,12 次迭代)距离实时应用仍有差距
RAFT 通过全对相关体积、循环 GRU 更新算子和单分辨率流场三大创新,在 Sintel 和 KITTI 基准上确立了光流估计的新 SOTA,同时保持了参数效率和训练效率。其设计思想——学习优化而非端到端映射——为其他视觉任务提供了新的架构范式。