Flow4Agent——光流运动先验的长视频理解
引言: Flow4Agent 是首个将光流运动先验用于 LLM 视频理解的框架。核心创新包括:(1)时间粒度优化(TGO):利用粗光流聚类视频事件,结合语义先验筛选关键场景;(2)运动 Token 剪枝(MTP):利用细粒度光流剪枝帧内冗余 token。在 Video-MME 达到 64.7%,MLVU 达到 71.4%,LongVideoBench 达到 60.4%,均为 SOTA。
✈️ Flow4Agent 算法介绍
多模态大语言模型(MLLM)在视频理解领域取得显著进展,但面临一个核心挑战——长视频的时空冗余。对于小时级视频,均匀采样意味着至少一分钟视频仅分配一帧,导致大量信息丢失;而密集采样又受限于 MLLM 的上下文长度约束。
现有方法主要依赖语义先验提取关键视频内容,如使用 CLIP 模型检索相关帧或生成密集字幕供 LLM 推理。但这种依赖存在两个关键问题:
- 依赖用户指令细节:当查询信息有限时,检索效果大幅下降
- 受限于先验模型:CLIP 或字幕模型的误差会传播并扭曲后续理解
本文引入一个被忽视的先验——光流运动信息,提出 Flow4Agent 框架。相比语义先验,运动先验具有独特优势:不依赖用户指令、计算成本低、直接反映场景动态变化。

Flow4Agent 从帧间和帧内两个层面解决冗余问题,分别由时间粒度优化(TGO)和运动 Token 剪枝(MTP)两个模块实现。
🚀 Flow4Agent 算法流程
Flow4Agent 的核心思想是利用光流从粗到细地提取关键视频内容:TGO 模块使用粗光流进行事件划分,MTP 模块使用细粒度光流进行帧内 token 筛选。
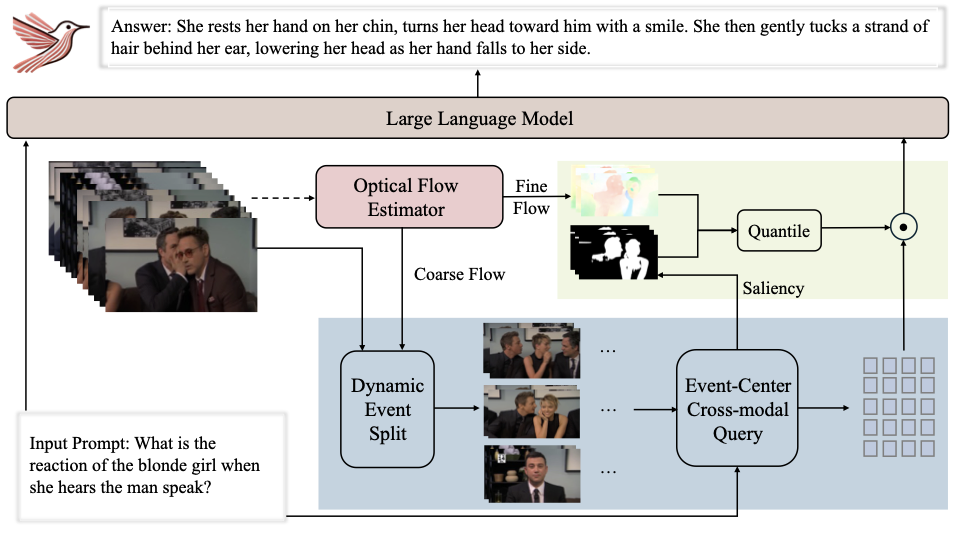
时间粒度优化(TGO)
均匀帧采样忽略时间结构动态,导致内容多样性不足:帧数多的事件被过度采样(即使缺乏动态变化),帧数少的关键事件可能被遗漏。TGO 模块通过两阶段时空分解解决这一问题。
动态事件划分:设计运动感知的色彩分析策略将视频划分为时间单元。
第一阶段使用 HSV 空间帧间差异进行粗划分。相比 RGB 空间,HSV 对光照变化不敏感,像素值变化更能反映实际事件动态。计算连续帧的均方误差,超过阈值则标记为边界:
V′ = {Φ(It) ∣ t ∈ ℕ} ΔV′ = {∥It + 1′ − It′∥2 ∣ t ∈ ℕ} C = {It ∣ ΔVt′ > θ, t ∈ ℕ}
其中 Φ 为 HSV 变换,C 为粗选边界集合。
第二阶段利用光流精确划分。对每个候选边界,计算时间窗口内相邻 M 帧的光流,若最大幅值超过阈值则确认边界:
其中 ℰ 为光流计算函数(使用 SeaRAFT,仅需少量迭代即可获得粗光流),S 为最终事件划分结果。
事件中心跨模态查询:划分事件后,选取每个事件的中帧作为锚帧,利用语义先验选择关键事件。
传统方法直接使用 CLIP 检索 top-k 相似帧,但高度依赖先验模型准确性——查询相关事件未必具有最高的相似度得分。因此引入两个约束:
min len(Sout)
其中 α(Si) 定义事件的显著性水平。当用户指令信息充足时,相关事件被独立选中;当指令缺乏细节时,约束确保所有重要场景不被遗漏,同时过滤完全无关的低显著性场景。
运动 Token 剪枝(MTP)
帧间冗余之外,同一场景内的帧存在大量帧内冗余——背景基本不变,关键信息集中在少量变化的前景。MTP 模块利用细粒度光流筛选动态密集的 token。
给定帧 It,计算与下一帧的光流,包含主体运动和全局运动(相机/背景移动)。为消除相机运动干扰,基于特征点进行单应性矩阵补偿。随后利用显著性检测获取主要运动区域,选择运动幅值前 k%(实践中 k = 50)的像素对应的 token:
ft = ℰ(It, It + 1) ft* = ft − ℋ(It, It + 1, ft) mt = 𝕀(∥ft*∥ ⊙ st ≥ Q0.5(∥ft*∥ ⊙ st)) qt = pt ⊙ mt
其中 ℋ 为基于单应性矩阵的相机运动计算,st 为显著性检测图,⊙ 为 Hadamard 积,Q0.5 为选择前 50% 动态像素的分位数函数。
采样策略:锚帧保留所有 token 以维护完整上下文,相邻帧应用 MTP 进行精细采样。关键事件及其邻接事件被标记为优先采样事件,采样帧数与事件长度成正比。
🎯 训练细节与实验结果
实现细节
基于 LLaVA-Video-Qwen 扩展 Flow4Agent。图像输入分辨率 336,LLM 最大上下文长度 8k,初始采样帧数 64。光流模型使用 SeaRAFT,TGO 模块 4 次迭代(粗光流),MTP 模块 12 次迭代(细粒度光流)。语义先验复用基座模型的 SigLiP 编码器。
主实验结果
| 模型 | Size | NextQA | EgoSchema | PercepTest | MLVU | L-VideoBench | VideoMME Long | VideoMME Overall |
|---|---|---|---|---|---|---|---|---|
| GPT4-V | - | - | 55.6 | - | - | 59.1 | 56.9 | 60.7 |
| Video-LLaVA | 7B | - | 38.4 | - | 47.3 | 39.1 | 38.1 | 40.4 |
| LLaVA-OneVision | 7B | 79.4 | 60.1 | 57.1 | 64.7 | 56.4 | 46.7 | 58.2 |
| LLaVA-Video | 7B | 83.2 | 57.3 | 67.9 | 70.8 | 58.2 | 50.6 | 62.6 |
| Apollo | 7B | - | - | 67.3 | 70.9 | 58.5 | - | 61.3 |
| Flow4Agent | 7B | 84.0 | 61.4 | 69.6 | 71.4 | 60.4 | 54.2 | 64.7 |
长视频 SOTA:Flow4Agent 在三个长视频基准上均取得最佳:Video-MME 64.7%(比 LLaVA-Video 提升 2.1%)、MLVU 71.4%、LongVideoBench 60.4%。在超过 30 分钟的视频上,比 LLaVA-OneVision 高 7.5%,比 224k 上下文的 LongVA 高 6.6%。
消融分析
模块贡献:
| DES | ECQ | MTP | Short | Medium | Long | Overall |
|---|---|---|---|---|---|---|
| 75.9 | 61.2 | 50.6 | 62.6 | |||
| ✓ | 77.0 | 61.7 | 50.8 | 63.2 | ||
| ✓ | 75.8 | 62.3 | 52.0 | 63.4 | ||
| ✓ | ✓ | 77.1 | 62.2 | 52.9 | 64.0 | |
| ✓ | 75.9 | 61.5 | 52.4 | 63.3 | ||
| ✓ | ✓ | ✓ | 77.2 | 62.6 | 54.2 | 64.7 |
TGO 模块的两个组件(DES 和 ECQ)分别为短视频和长视频带来显著增益,MTP 模块进一步增强长视频理解。
跨基座模型泛化:
| 基座模型 | Context | LLM | Frames | 原始 | +Flow4Agent |
|---|---|---|---|---|---|
| LLaVA-NeXT | 4k | 7B | 16 | 44.9 | 47.0 |
| LLaVA-OneVision | 8k | 7B | 32 | 58.2 | 59.9 |
| Qwen2-VL | 32k | 7B | 64 | 61.7 | 63.9 |
| LLaVA-Video | 8k | 7B | 64 | 62.6 | 64.7 |
| LLaVA-Video | 8k | 72B | 64 | 67.1 | 69.0 |
Flow4Agent 作为模型无关方法,在各种基座模型、上下文长度和 LLM 规模上均带来一致提升。
先验模型选择:
| 光流模型 | Iter-TGO | Iter-MTP | Long | Overall |
|---|---|---|---|---|
| NeuFlow | 4 | 12 | 53.0 | 64.1 |
| StreamFlow | 4 | 12 | 53.9 | 64.5 |
| Sea-RAFT | 4 | 12 | 54.2 | 64.7 |
| Sea-RAFT | 12 | 12 | 54.4 | 64.6 |
| Sea-RAFT | 4 | 4 | 53.3 | 64.2 |
粗细光流最优配置:TGO 模块仅需 4 次迭代获得粗光流即可有效划分事件,MTP 模块需要 12 次迭代获得细粒度光流进行精确 token 剪枝。这种「粗划分、细剪枝」的配置在效率和精度间取得最佳平衡。
帧数影响:
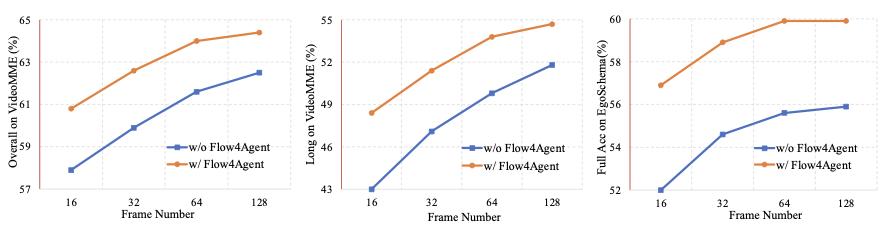
Flow4Agent 在任意帧数下均带来提升,帧数受限时优势更明显。且 Flow4Agent 用更少帧即可达到性能饱和,展现更高的帧效率。
可视化分析

TGO 模块有效区分不同场景(胶片线分隔),MTP 模块高效去除帧内冗余背景(灰色区域),同时保留关键变化(人物动作、面部表情)。
💡 洞察与结论
运动先验的独特价值:相比语义先验,光流运动信息不依赖用户指令细节,计算成本可控,直接反映场景动态。这使其成为长视频理解的关键补充先验。
粗细光流的协同设计:TGO 模块使用粗光流快速划分事件,MTP 模块使用细粒度光流精确剪枝。这种从粗到细的设计兼顾效率和精度。
事件中心优于帧中心:传统方法基于帧进行语义检索,Flow4Agent 先用运动先验聚类事件再进行语义筛选,天然去除冗余信息。
模型无关的广泛适用性:Flow4Agent 可即插即用地应用于各种 MLLM 架构,在不同上下文长度、LLM 规模和采样帧数下均有效。
局限与未来方向: 1. 光流计算开销:虽然 SeaRAFT 效率较高,但光流计算仍带来额外开销,未来可探索更轻量的运动表示 2. 动态事件阈值:当前阈值设计基于经验,对不同类型视频可能需要自适应调整 3. 多模态融合:如何更好地融合运动先验与语义先验仍有探索空间
Flow4Agent 首次将光流运动先验引入 LLM 视频理解,通过 TGO 和 MTP 两个模块从帧间和帧内两个层面解决冗余问题,在多个长视频基准上取得 SOTA 性能,展现了运动先验在视频理解中的巨大潜力。