Kimi-VL——技术报告详解
引言: Kimi-VL 是 Moonshot AI 推出的高效多模态视觉语言模型,采用 MoE 架构实现参数效率与性能的平衡,仅 2.8B 激活参数(LLM)+ 0.4B(ViT)即达到与更大模型相当的性能。支持 128K 上下文窗口,在 24 个公开基准中的 19 个上超越 Qwen2.5-VL-7B(后者激活参数是 Kimi-VL 的 2.59 倍)。Kimi-VL-Thinking-2506 在 MathVision 上达到 56.9%,超越 Qwen2.5-VL-72B 和 GPT-4o。
✈️ 引言
随着人工智能的快速发展,人类对 AI 助手的期望已超越传统纯语言交互,越来越与世界固有的多模态特性对齐。GPT-4o 和 Google Gemini 等原生多模态模型已经能够无缝感知和解释视觉输入。更进一步,OpenAI o1 系列和 Kimi k1.5 通过在多模态输入上进行更深更长的推理,推动了更复杂问题解决的边界。
Kimi-VL 的设计目标是构建一个高效的多模态模型,在保持强大性能的同时实现参数效率。通过 MoE 架构、128K 长上下文窗口和原生分辨率视觉编码器 MoonViT,Kimi-VL 在 OCR、数学推理、智能体任务、长文档和长视频理解等多个领域展现出卓越能力。
阅读提示: 本文按原文结构依次介绍模型架构、预训练流程、后训练方法和全面评估结果。Kimi-VL 在 MathVista(68.7%)、InfoVQA(83.2%)、ScreenSpot-Pro(34.5%)等基准上取得开源模型领先性能。
🏗️ 模型架构
Kimi-VL 采用标准的三组件架构:原生分辨率视觉编码器(MoonViT)、MLP 投影器和 MoE 大语言模型。
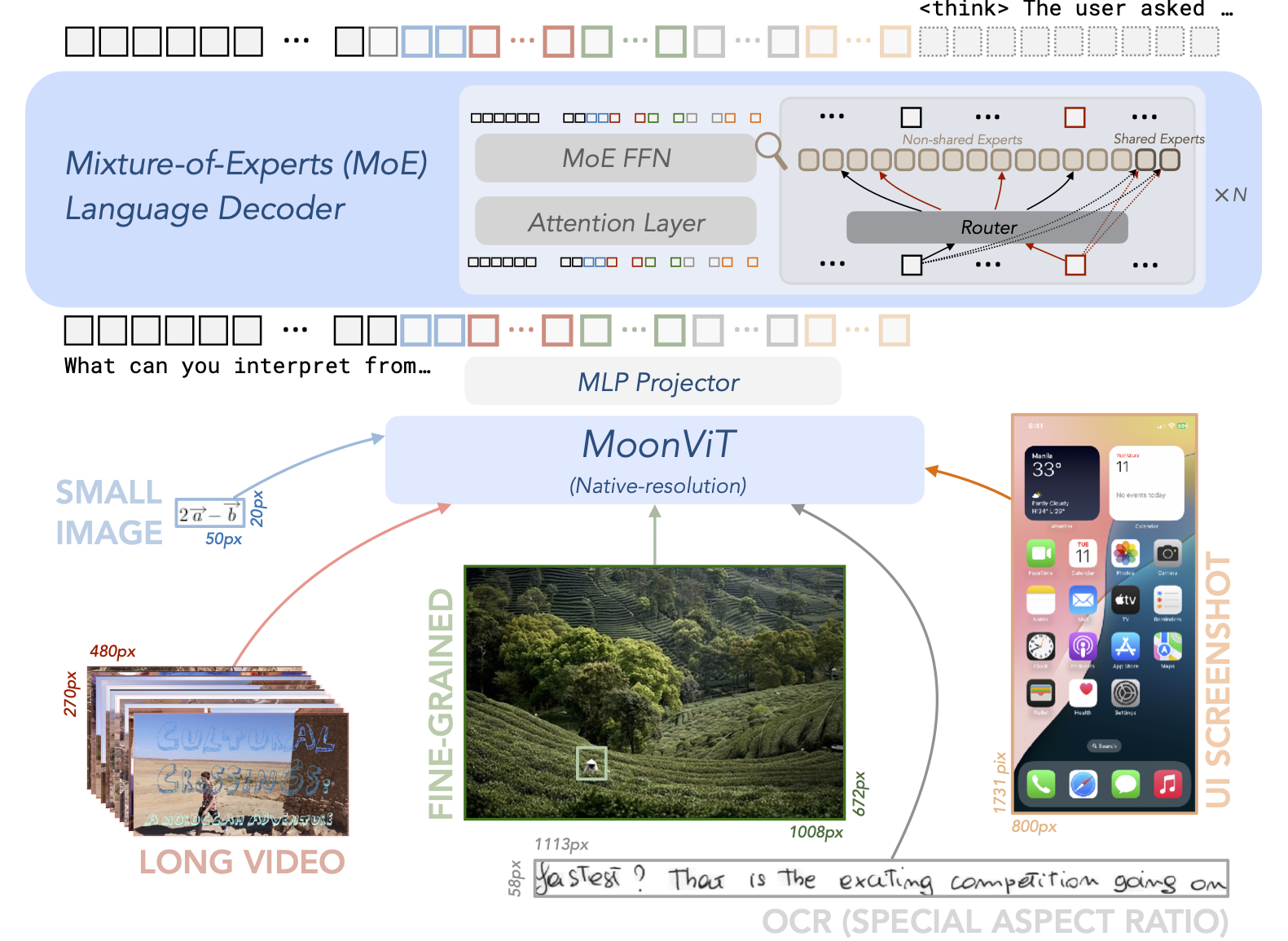
MoonViT:原生分辨率视觉编码器
MoonViT 是专为原生分辨率特征提取设计的视觉编码器,解决了固定分辨率处理导致的信息丢失问题。核心设计:
- 原生分辨率支持:采用 NaViT 的 patch packing 策略,支持任意分辨率图像输入
- 2D RoPE 位置编码:替代传统 1D 位置编码,更好地保留空间位置信息
- 架构参数:
- Patch Size:14
- Embed Dim:1152
- Depth:27
- Num Heads:16
- 参数量:约 400M
输入图像通过双线性插值调整至
MoE 大语言模型
Kimi-VL 采用 MoE 架构实现参数效率:
| 组件 | 参数量 |
|---|---|
| MoonViT | 0.4B |
| MLP 投影器 | - |
| LLM 总参数 | 16B |
| LLM 激活参数 | 2.8B |
| 总激活参数 | ~3.2B |
MoE 架构使 Kimi-VL 以仅 2.8B 激活参数达到与 7B+ 稠密模型相当的性能,训练吞吐量比 7B 稠密 VLM 高约 60%。
长上下文能力
Kimi-VL 支持 128K token 上下文窗口,通过两阶段扩展:
- 8K → 32K:RoPE 逆频率从 50,000 重置
- 32K → 128K:RoPE 逆频率重置为 800,000
Needle-in-a-Haystack 测试验证了长上下文能力:
| Haystack 长度 | (0, 2K] | (2K, 4K] | (4K, 8K] | (8K, 16K] | (16K, 32K] | (32K, 64K] | (64K, 128K] |
|---|---|---|---|---|---|---|---|
| 文本 NIAH | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 87.0 |
| 视频 NIAH | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 91.7 |
📊 预训练
预训练数据
Kimi-VL 的多模态预训练语料设计为提供高质量数据,使模型能够处理和理解文本、图像、视频等多种模态信息。数据分为六大类别:
字幕数据:提供基础的模态对齐和广泛的世界知识。整合 LAION、DataComp 等开源数据集和内部数据,严格限制合成字幕数据比例以减轻幻觉风险。
图文交错数据:增强多图像理解能力、提供详细图像知识、学习更长多模态上下文。有趣的是,交错数据还对维持语言能力有正向贡献。使用教科书、网页和教程等资源构建大规模内部数据。
OCR 数据:覆盖多语言文本、密集文本布局、网页内容和手写样本。遵循 OCR 2.0 原则,处理图表、表格、几何图、Mermaid 图和自然场景文本等多种光学图像类型。单页 OCR 数据外,还收集大量多页 OCR 数据激活长文档理解能力。
知识数据:从教科书、研究论文等学术材料构建多模态知识语料。精心策划的几何数据对发展视觉推理能力至关重要。使用布局解析器和 OCR 模型处理内容来源。
智能体数据:显著增强模型的定位和规划能力。建立平台管理虚拟机环境,收集截图和对应动作数据。动作空间按 Desktop、Mobile、Web 环境分类。收集人类标注的计算机使用轨迹,每个轨迹配有合成 Chain-of-Thought。
视频数据:在预训练、cooldown 和长上下文激活阶段引入大规模视频数据,实现两个核心能力:理解以图像为主导的长上下文序列(如小时级视频)、感知短视频片段中的细粒度时空对应关系。
文本数据:直接使用 Moonlight 中的数据,覆盖英语、中文、代码、数学与推理、知识五个域。
预训练阶段

Kimi-VL 预训练在 LLM 文本预训练后消耗 4.4T token。为保持文本能力,所有更新 LLM 的阶段都是联合训练阶段。
| 阶段 | 数据 | Token | 序列长度 | 可训练组件 |
|---|---|---|---|---|
| ViT 训练 | Alt text、合成字幕、定位、OCR | 2T + 0.1T | 8,192 | ViT |
| 联合预训练 | 文本、知识、交错、视频、智能体 | 1.4T | 8,192 | ViT & LLM |
| 联合 Cooldown | 高质量文本/多模态、学术来源 | 0.6T | 8,192 | ViT & LLM |
| 联合长上下文 | 长文本、长视频、长文档 | 0.3T | 32K→128K | ViT & LLM |
ViT 训练阶段:MoonViT 在图文对上训练,文本组件包括图像 alt text、合成字幕、定位边界框和 OCR 文本。采用两个目标:SigLIP 损失和条件字幕生成的交叉熵损失:
其中
联合预训练阶段:混合纯文本数据(从与初始 LLM 相同分布采样)和多种多模态数据。从加载的 LLM 检查点继续训练,使用相同学习率调度器。初始步骤仅使用语言数据,然后多模态数据比例逐渐增加。
联合 Cooldown 阶段:使用高质量语言和多模态数据集继续训练。语言部分引入合成数据在数学推理、知识任务和代码生成上带来显著提升。多模态部分采用问答合成和高质量子集重放,过滤和重写学术视觉或视觉语言数据源为问答对。
联合长上下文激活阶段:扩展上下文长度从 8K 到 128K,RoPE 嵌入逆频率从 50,000 重置到 800,000。分两个子阶段,每个扩展四倍。长数据比例过滤上采样到 25%,剩余 75% 回放较短数据。长数据包含长文本、长交错数据、长视频和长文档。
🚀 后训练
监督微调(SFT)
使用 ChatML 格式进行指令优化,同时保持与 Kimi-VL 的架构一致性。优化 LLM、MLP 投影器和视觉编码器,使用纯文本和视觉语言 SFT 数据混合。监督仅应用于答案和特殊 token,系统和用户提示被掩码。
两阶段训练:
- 32K 阶段:学习率从
衰减到 - 128K 阶段:学习率重新预热到
后衰减到
指令数据
增强模型的对话能力和指令遵循能力。非推理任务(图表解释、智能体定位、OCR、图像对话等)通过人工标注构建种子数据集训练种子模型,然后收集多样化提示,使用种子模型生成多个响应,标注者排序并精化最佳响应。推理任务使用拒绝采样扩展 SFT 数据集。
推理数据
精心构建用于激活和增强模型多模态推理能力。通过类似拒绝采样的生成流水线收集合成高质量长 CoT 数据。首先收集需要多步推理的带标注 QA 数据,然后使用 Kimi k1.5 强大长 CoT 模型采样多条详细推理轨迹。错误推理链根据模型评估和基于规则的奖励过滤。
Long-CoT 监督微调
使用精化的 RL 提示集,通过提示工程构建小而高质量的长 CoT 预热数据集。数据集封装关键认知过程:
- 规划:模型系统性地概述执行前的步骤
- 评估:对中间步骤进行批判性评估
- 反思:使模型能够重新考虑和精化方法
- 探索:鼓励考虑替代解决方案
通过在这个预热数据集上进行轻量 SFT,有效引导模型内化这些多模态推理策略。
强化学习
采用在线策略镜像下降变体作为 RL 算法,迭代精化策略模型
其中
效率增强策略:
- 基于长度的奖励:惩罚过长响应,缓解过度思考问题
- 课程采样:利用难度标签聚焦最有教学价值的示例
- 优先采样:利用每实例成功率优化学习轨迹

🎯 评估结果
与 SOTA 模型对比
Kimi-VL 在多个基准上与领先 VLM 对比,尽管架构更参数高效(2.8B+0.4B 激活参数),在多个关键领域展现竞争或优越性能。
大学级学术问题:
| 基准 | Kimi-VL-A3B | DeepSeek-VL2 | Qwen2.5-VL-7B | Gemma3-12B |
|---|---|---|---|---|
| MMMU-val | 57.0 | 51.1 | 58.6 | 59.6 |
| VideoMMMU | 52.6 | 44.4 | 47.4 | 57.2 |
| MMVU-val | 52.2 | 52.1 | 50.1 | 57.0 |
通用视觉能力:
| 基准 | Kimi-VL-A3B | Qwen2.5-VL-7B | Gemma3-12B | GPT-4o |
|---|---|---|---|---|
| MMBench-EN | 83.1 | 82.6 | 74.6 | 83.1 |
| AI2D | 84.9 | 83.9 | 78.1 | 84.6 |
| MMVet | 66.7 | 67.1 | 64.9 | 69.1 |
| RealWorldQA | 68.1 | 68.5 | 59.1 | 75.4 |
数学推理:
| 基准 | Kimi-VL-A3B | Qwen2.5-VL-7B | DeepSeek-VL2 | GPT-4o |
|---|---|---|---|---|
| MathVista | 68.7 | 68.2 | 62.8 | 63.8 |
| MathVision | 21.4 | 25.1 | 17.3 | 30.4 |
OCR 与文档理解:
| 基准 | Kimi-VL-A3B | Qwen2.5-VL-7B | DeepSeek-VL2 | GPT-4o |
|---|---|---|---|---|
| InfoVQA | 83.2 | 82.6 | 78.1 | 80.7 |
| OCRBench | 867 | 864 | 811 | 815 |
OCR 能力领先:Kimi-VL 在 InfoVQA(83.2%)和 OCRBench(867)上超越所有对比模型包括 GPT-4o,展现出卓越的文字识别和文档理解能力。
智能体定位与多轮交互:
| 基准 | Kimi-VL-A3B | Qwen2.5-VL-7B | GPT-4o |
|---|---|---|---|
| ScreenSpot-V2 | 92.8 | 86.8 | 18.1 |
| ScreenSpot-Pro | 34.5 | 29.0 | 0.8 |
| OSWorld | 8.22 | 2.5 | 5.03 |
| WindowsAgentArena | 10.4 | 3.4 | 9.4 |
智能体能力突出:Kimi-VL 在 ScreenSpot-Pro(34.5%)上大幅领先 Qwen2.5-VL-7B(29.0%)和 GPT-4o(0.8%),在 OSWorld(8.22%)和 WindowsAgentArena(10.4%)上均超越 GPT-4o。这表明模型具有强大的 GUI 理解和操作能力。
长文档与长视频理解:
| 基准 | Kimi-VL-A3B | Qwen2.5-VL-7B | GPT-4o |
|---|---|---|---|
| MMLongBench-Doc | 35.1 | 29.6 | 42.8 |
| Video-MME (w/o sub) | 67.8 | 65.1 | 71.9 |
| MLVU-MCQ | 74.2 | 70.2 | 64.6 |
| LongVideoBench | 64.5 | 56.0 | 66.7 |
视频感知:
| 基准 | Kimi-VL-A3B | Qwen2.5-VL-7B | GPT-4o |
|---|---|---|---|
| EgoSchema | 78.5 | 65.0 | 72.2 |
| VSI-Bench | 37.4 | 34.2 | 34.0 |
| TOMATO | 31.7 | 27.6 | 37.7 |
Kimi-VL-Thinking:推理扩展版本
通过长 CoT 激活和强化学习训练的思考模型,显著提升多模态推理能力:
| 基准 | Kimi-VL-Thinking | Kimi-VL | 提升 |
|---|---|---|---|
| MathVista | 71.3 | 68.7 | +2.6% |
| MMMU-val | 61.7 | 57.0 | +4.7% |
| MathVision | 36.8 | 21.4 | +15.4% |
Kimi-VL-Thinking 在推理基准上与 SOTA 模型竞争:
| 基准 | Kimi-VL-Thinking | GPT-4o | Qwen2.5-VL-7B | QVQ-72B |
|---|---|---|---|---|
| MathVision | 36.8 | 30.4 | 25.1 | 35.9 |
| MathVista | 71.3 | 63.8 | 68.2 | 71.4 |
| MMMU-val | 61.7 | 69.1 | 58.6 | 70.3 |
测试时扩展:Kimi-VL-Thinking 展现出强大的测试时扩展特性。增加最大思考 token 长度可在所有三个基准上一致提升准确率。在 MathVision 上,准确率从 1K token 的 18.7% 稳步上升到 16K token 的 36.8%。但在 MathVista 上,性能在 4K token 时饱和(70.9%),表明该任务所需推理深度已在相对短的上下文中捕获。
Kimi-VL-Thinking-2506:集成思考模型
更新的推理变体不仅更智能,还将 Kimi-VL-A3B-Instruct 的感知、视频、长文档和 OS 智能体能力集成到思考模型中。
推理能力提升:
| 基准 | Kimi-VL-Thinking | Kimi-VL-Thinking-2506 | 提升 |
|---|---|---|---|
| MathVision | 36.8 | 56.9 | +20.1% |
| MathVista | 71.3 | 80.1 | +8.4% |
| MMMU-Pro | 43.0 | 46.3 | +3.2% |
| VideoMMMU | 55.5 | 65.2 | +9.7% |
Kimi-VL-Thinking-2506 推理突破:在 MathVision 上达到 56.9%,超越 Qwen2.5-VL-72B(38.1%)和 Kimi k1.5(38.6%);在 MathVista 上达到 80.1%,超越所有对比模型。同时平均输出 token 长度减少约 20%(如 MMMU-val:2.9K→2.4K),更高效用户友好。
非推理任务能力:
| 基准 | Kimi-VL-A3B-Instruct | Kimi-VL-Thinking-2506 |
|---|---|---|
| MMBench-EN | 82.9 | 84.4 |
| MMStar | 61.7 | 70.4 |
| ScreenSpot-Pro | 35.4 | 52.8 |
| OSWorld-G | 41.6 | 52.5 |
| MMLongBench-Doc | 35.1 | 42.1 |
MoonViT 在 2506 版本上持续训练(最大输入像素 3.2M),在高分辨率感知和 OS 定位基准上大幅提升:ScreenSpot-Pro(52.8%)、OSWorld-G(52.5%),成为首个匹配 GPT-4o 的开源模型。
💡 结论与局限
Kimi-VL 是一个平衡多模态和纯文本预训练/后训练的 VLM,采用 MoE 架构实现可扩展效率。128K 扩展上下文窗口支持长文本和视频中的精确检索,原生分辨率编码器 MoonViT 在超高分辨率视觉任务中保持高准确率和低计算开销。
Kimi-VL 在多模态、长上下文和高分辨率任务中展现出强大的适应性和效率,在 MathVista、InfoVQA、ScreenSpot-Pro、OSWorld 等多个基准上取得开源模型领先性能。
局限与未来工作:
- 模型规模:当前模型规模对高度专业化或领域特定问题仍受限,难以处理极复杂场景
- 推理上限:推理能力虽已强大,但对需要多步推理或更深上下文理解的复杂任务尚未达到理论上限
- 长上下文能力:注意力层参数仅相当于 3B 模型,对于极长序列或大容量上下文信息的高级应用仍不足
未来将通过扩大模型规模、扩展预训练数据和增强后训练算法应对这些挑战。下一步包括优化 Kimi-VL 并发布更大版本,以及精化后训练和测试时扩展机制以获得更好的思考模型。