VideoAuto-R1——按需推理的视频理解框架
引言: 该研究提出 VideoAuto-R1,采用「思一次、答两次」训练范式的自适应视频推理框架。它解决了「CoT 推理在视频任务中效果有限且成本高」「自适应推理在视频领域不稳定」「直接回答常可匹敌 CoT 性能」等问题。在 VideoMME(67.3%)、VideoMMMU(58.6%)、时序定位基准上实现 SOTA,响应长度从 149 降至 44 tokens。
✈️ VideoAuto-R1 算法介绍
视频理解任务近年来广泛采用链式思维(CoT)推理,通过显式的逐步分析提升模型性能。然而,作者通过系统分析发现了一个反直觉的现象:对于 RL 训练的视频推理模型,直接回答策略(不提供解释)常与 CoT 推理匹配,甚至在某些情况下超越 CoT 性能。这一发现挑战了「复杂推理总是必要的」的假设。
现有自适应推理策略主要面向文本和图像领域,通常通过监督微调或强化学习学习模式切换策略。将这些策略直接迁移到视频面临显著挑战:视频任务中显式推理与准确率的相关性较弱,且真正「必须推理」的视频样本相对稀缺。在实验中,训练时强制指定推理或不推理决策常导致模型崩溃(始终推理或始终不推理),测试时泛化能力差。
VideoAuto-R1 提出了「思一次、答两次」机制来解决这一问题。训练时采用 answer → think → answer 模板,模型首先生成初始答案,然后进行推理,最后输出审查后的答案。推理时采用基于置信度的早期退出策略,根据初始答案的置信度决定是否继续推理。这种设计解耦了「何时思考」(推理时决定)和「如何思考」(训练时学习)。
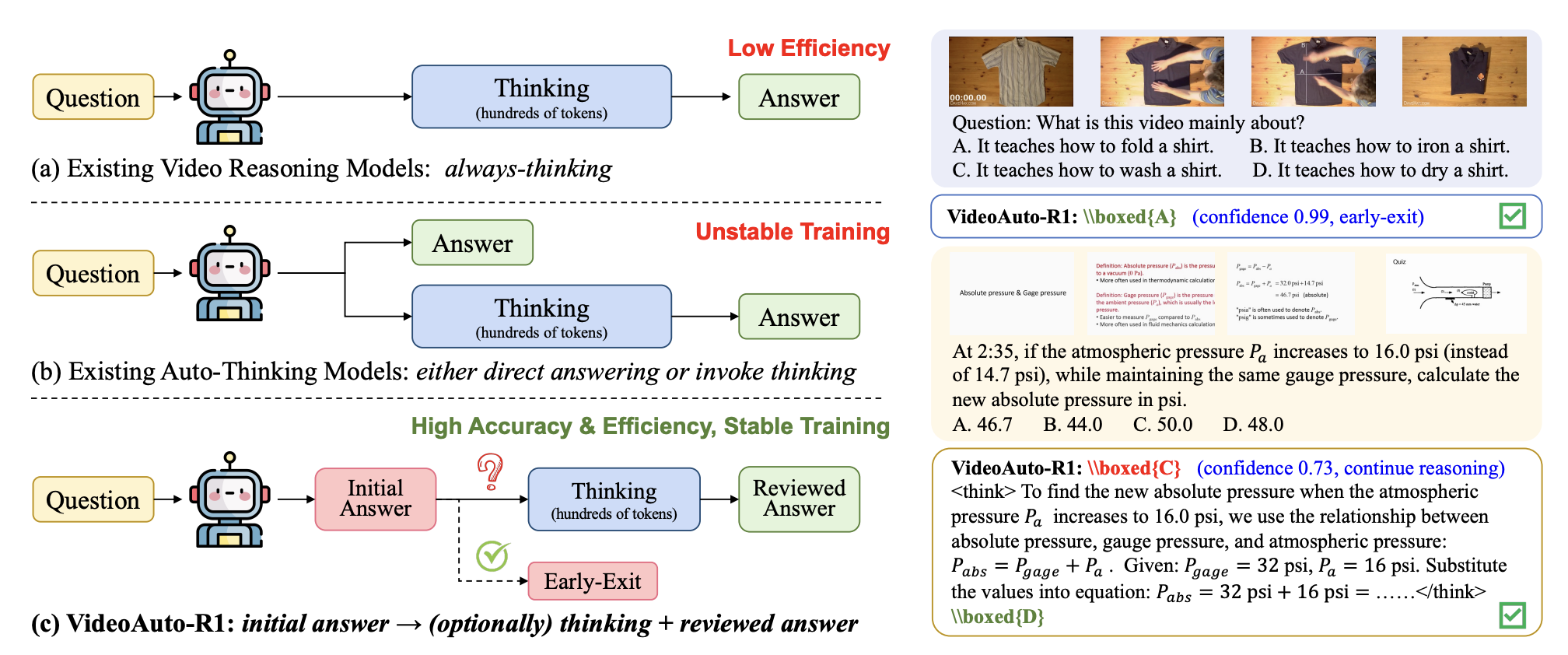
🚀 VideoAuto-R1 算法流程
Thinking Once, Answering Twice
现有自适应推理方法常学习二元目标(推理或不推理),这需要精心平衡数据和超参数。视频领域高质量推理示例稀缺,加剧了不稳定性。VideoAuto-R1 采用了不同视角:真正的 CoT 应建立在初始答案之上,简单问题的初始答案应足够,困难问题应在同一生成中验证和修正。
输出格式严格遵循可验证模板:\boxed{a_1} |||{r}| \boxed{a_2}。a1 和 a2 是简短的可验证答案,r 是自由形式的理由。强制要求恰好两个 \boxed{...} 块和一个 |||{...}| 块。系统提示经过精心设计,无需冷启动 SFT 即可实现此输出格式。
回退容忍设计用于处理数学或符号复杂问题。模型无法在不经中间推理的情况下产生正确 a1 时,可在第一个框中输出指定回退字符串「Let’s analyze the problem step by step」,然后继续推理并生成最终答案 a2。此设计保留输出语法,避免虚假猜测,确保早期退出机制清晰可解释。
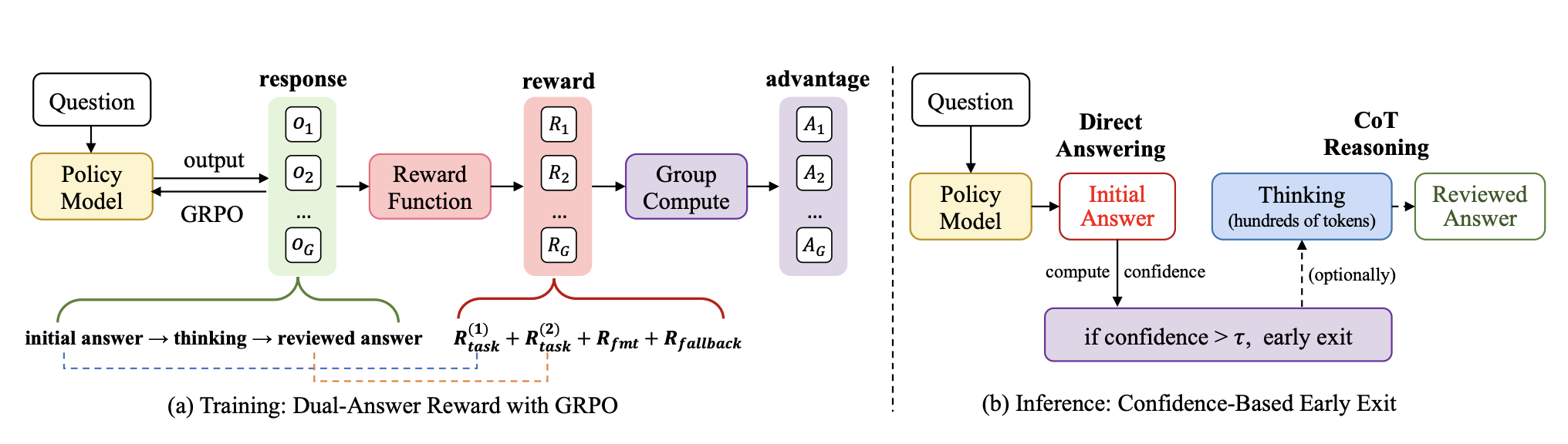
双答案奖励机制
训练遵循 GRPO 框架,但引入新的「双答案」奖励监督初始和审查后的答案。总奖励定义为:
R = w1Rtask(1)(a1) + w2Rtask(2)(a2) + λRfmt + αRfallback
其中 w2 > w1 ≥ 0,λ, α ≥ 0 是权重系数。w2 更大的权重用于鼓励更准确的审查后答案,同时仍激励良好的初始答案。此设计也惩罚了第一个答案正确但第二个答案错误的情况,推动模型提高整体可靠性。
Rfmt 确保输出格式遵循要求的 answer → think → answer 模板。Rfallback ∈ {0, 1} 是回退奖励,当 a1 是指定回退字符串且 a2 正确时给予奖励。这抑制困难问题中 a1 的低置信猜测,奖励诚实的推迟随后准确的推理。
基于置信度的早期退出
推理时采用简单有效的早期退出机制,基于规则检查第一个框定答案是否有足够置信度以跳过剩余生成。令 a1 = (t1, …, tL) 为第一个框内的 token,长度归一化的置信度分数为:
给定置信度阈值 τ,若 s(a1) ≥ log τ 则接受 a1 并终止解码;否则继续生成理由 r 和第二个答案 a2。阈值 τ 控制准确率-效率权衡,可在保留集上确定。实践中,单一固定阈值在多样化视频 QA 基准上表现良好。
训练与推理细节
训练细节:基础模型为 Qwen2.5-VL-7B-Instruct 和 Qwen3-VL-8B-Instruct。最大视频 token 数为 4,096(Qwen2.5)或 128K(Qwen3),最大帧数为 256。学习率为 1 × 10−6,权重衰减 0.01。奖励权重设置为 w1 = 0.9、w2 = 1.1、λfmt = 1、α = 0.3。全局 batch size 为 256,训练 1 个 epoch。Rollout size 为 16,温度设为 1.0。
推理细节:采用贪婪解码(温度 0),最大响应长度 4,096 tokens。早期退出阈值设为 τ = 0.97。
🎯 实验结果
主要结果
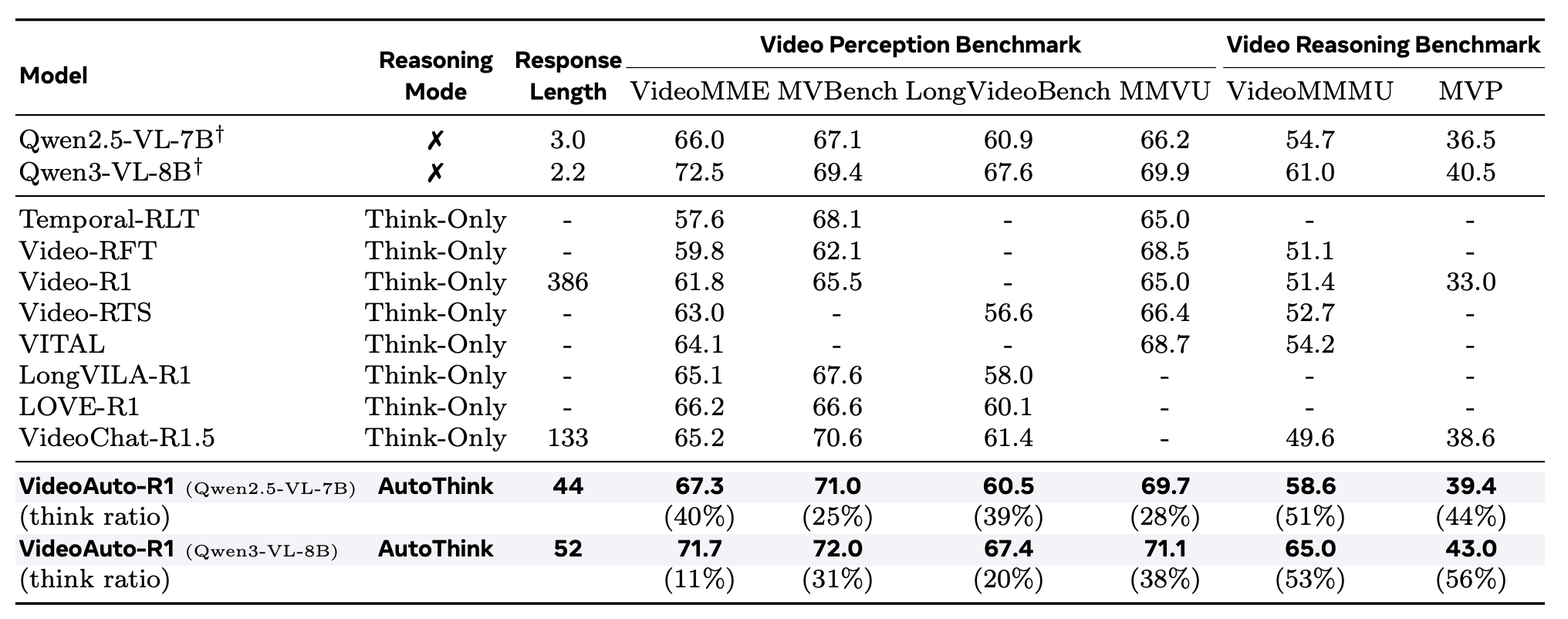
视频 QA 基准:VideoAuto-R1 在感知和推理基准上均实现 SOTA。基于 Qwen2.5-VL 时,VideoMME 准确率达 67.3%,超越 Video-R1 5.5%、VITAL 3.2%、VideoChat-R1.5 2.1%。推理密集的 VideoMMMU 基准上,准确率从 54.7% 提升至 58.6%(+3.9%),更难的 MVP 基准成对准确率从 36.5% 提升至 39.4%。
基于 Qwen3-VL 时,性能进一步提升,VideoMMMU 达到 65.0%。这些结果证明了自适应推理对视频理解的有效性。
效率提升:相比 Video-R1 的 386 token 响应,VideoAuto-R1 平均仅生成 44 tokens,减少 3.3 倍。模型根据任务复杂度自适应触发推理:感知导向的 MVBench 上推理模式激活率仅 25%,推理密集的 VideoMMMU 上升至 51%。这表明模型能对真正具有挑战性的查询调用 CoT,突显自适应推理的效率优势。
时序定位基准:双答案 GRPO 训练后,初始框定预测已足够准确。后续 CoT 主要提供解释性理解而不提升定位性能,因此默认采用早期退出。VideoAuto-R1 将 Charades-STA 的 mIoU 从 52.9% 提升至 60.0%,ActivityNet 的 mIoU 从 26.9% 提升至 47.6%,NExT-GQA 的 QA 准确率从 53.3% 提升至 80.6%。
消融研究
训练策略对比:四种训练策略对比显示:(1)SFT 仅带来轻微增益;(2)不思考的 RL 在格式敏感任务(如 Charades-STA)上表现更好;(3)思考的 RL 大幅提升推理密集基准(如 VideoMMMU),但使平均响应长度从 2.5 膨胀至 149 tokens,对感知导向任务增益有限;(4)VideoAuto-R1 超越所有变体,同时将平均响应长度降至 44 tokens。
自适应推理策略对比:与基于训练的策略(如 AdaptThink)对比,VideoAuto-R1 的基于推理的选择表现更稳定。基于训练的方法在 MVBench 上甚至不如不推理基线,且容易模式崩溃。VideoAuto-R1 始终超越不推理基线,接近始终思考的准确率但响应长度大幅缩短。
奖励设计消融:不对称权重(w2 > w1)优于等权重 1 : 1。添加回退奖励 α 进一步提升推理基准性能,实现 SOTA 结果。w1 : w2 = 0.9 : 1.1 且 α = 0.3 为最优配置。
早期退出阈值分析:随着阈值 τ 增加,早期退出变得更保守,think 比率单调上升。在推理密集基准上,更高的 τ 持续提升准确率并增加推理使用。在感知导向的 VideoMME 上,准确率在阈值范围内基本不变,而 think 比率仍增加,表明简单感知查询从额外推理中收益递减。
数据集与基准
训练数据涵盖视频数据集(VideoMME、MVBench、LongVideoBench、MMVU、VideoMMMU、MVP)、时序定位数据集(Charades-STA、ActivityNet、NExT-GQA)和图像推理数据集(MathVista、MathVision、MathVerse、MMMU)。这种多样化数据构成确保模型具备广泛的视频理解和推理能力。
💡 洞察与结论
直接推理的价值通过系统研究得以验证。对于 RL 训练的视频模型,直接回答常匹配或超越 CoT 性能,这挑战了「更长思维链总是更好」的假设。视频理解任务更注重视觉感知而非显式逐步思考,感知准确后剩余符号推理往往较浅。这一观察对视频领域具有重要意义:盲目应用 CoT 可能导致过度思考,反而降低性能。
思一次答两次的设计巧妙解耦了训练目标和推理策略。训练时模型同时学习直接回答和推理修正后的答案,推理时通过置信度决定使用哪一个。这种解耦带来灵活性:计算充足时可始终使用审查后的答案,预算紧张时可回退到初始直接答案,仍受益于 RL 训练。用户可灵活控制准确率与效率权衡。
置信度作为自检信号表明模型对其输出有内部分置信度估计能力。长度归一化的置信度分数与需要推理的样本高度相关,为自适应推理提供稳定可靠的判据。这一机制无需外部校准器,直接利用模型自身的输出分布,实现简单有效的早期退出策略。
数据集特异性观察显示视频任务存在感知-推理谱系。感知导向基准(MVBench、MMVU)初始答案置信度高(93%),推理激活率低(25-39%),推理增益微小。推理密集基准(VideoMMMU)初始置信度较低(87%),推理激活率高(51%),推理带来明显收益。这种谱系表明「一刀切」的推理策略次优,自适应更符合任务本质。
局限性与未来方向:当前框架依赖置信度阈值,该值需要在保留集上确定。未来可探索自适应阈值机制或端到端学习的退出策略。此外,当前研究聚焦视频理解,但框架设计具有通用性,可扩展到其他模态(图像、音频)和任务类型。另一个方向是研究更复杂的输出格式,如多轮迭代推理或结构化推理图表示。