VideoMind——基于 Chain-of-LoRA 的长视频推理框架
引言: VideoMind 是一个基于角色工作流和 Chain-of-LoRA 的视频语言 Agent,通过「Planner-Grounder-Verifier-Answerer」四角色协作实现长视频的时序锚定推理。该方法解决了「时序锚定理解需求」「视觉 CoT 无法显式定位」「多模态推理能力缺失」等核心问题,在 14 个基准上达到 SOTA,包括 Grounded VideoQA、Video Temporal Grounding 和 General VideoQA 等任务。
✈️ VideoMind 算法介绍
视频理解与图像理解存在本质差异:视频具有独特的时序维度,需要「时序锚定理解」(temporal-grounded understanding)。这意味着答案必须与特定视频时刻的视觉证据直接关联,而非对整个视频的泛泛描述。
然而,现有的多模态大语言模型主要聚焦于图像理解,其视觉 Chain-of-Thought(CoT)方法虽然能够生成中间推理步骤,但无法显式定位或重访视频序列的前面部分。当需要基于特定时刻回答问题时,这些方法往往缺乏时序感知能力。
为此,VideoMind 提出基于角色的 Agent 工作流,模拟人类理解长视频的自然过程:分解复杂任务、定位相关时刻、验证细节信息、合成最终答案。这种渐进式策略解决了时序锚定推理的独特挑战,实现了答案与视觉证据的直接关联。
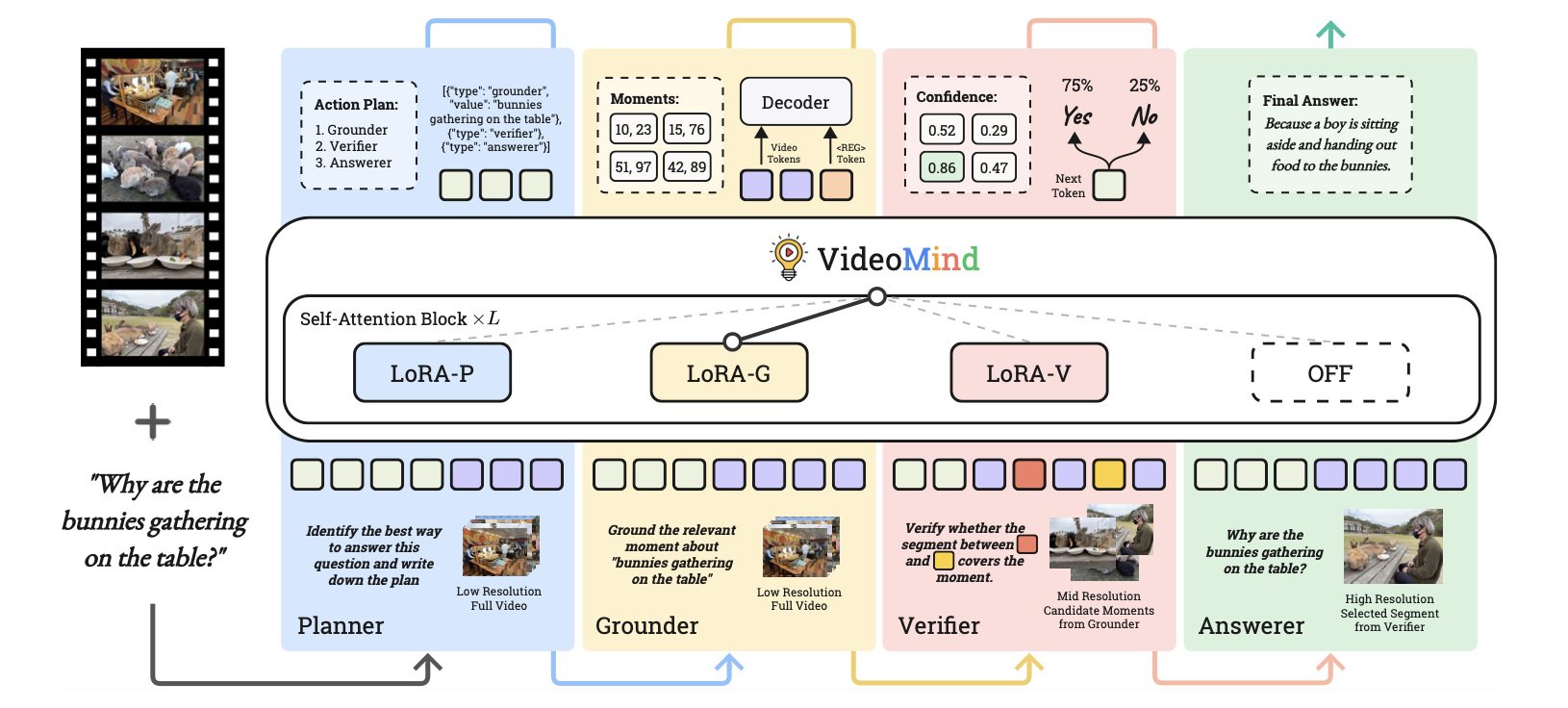
🚀 VideoMind 管道流程
VideoMind 以 Qwen2-VL 为基础模型,设计了四个专用角色:Planner 负责协调工作流,Grounder 负责定位时刻,Verifier 负责验证有效性,Answerer 负责生成答案。通过 Chain-of-LoRA 策略,单一基础 MLLM 配合轻量级 LoRA 适配器即可实现多角色无缝协作。
Planner
Planner 是整个工作流的协调者,负责决定其他角色的调用顺序和模式。每个函数调用格式化为 JSON 对象 {"type": <role>, "value": <argument>},Planner 根据任务类型动态生成调用序列。
Planner 定义三种计划模式以适应不同任务需求:
- Grounding & Answering: 需要同时生成回答和时间戳,适用于 NExT-QA 等时序推理问题
- Grounding Only: 仅定位相关时刻,适用于 QVHighlights 等时刻检索任务
- Answering Only: 直接观看整个视频回答,适用于总结类问题
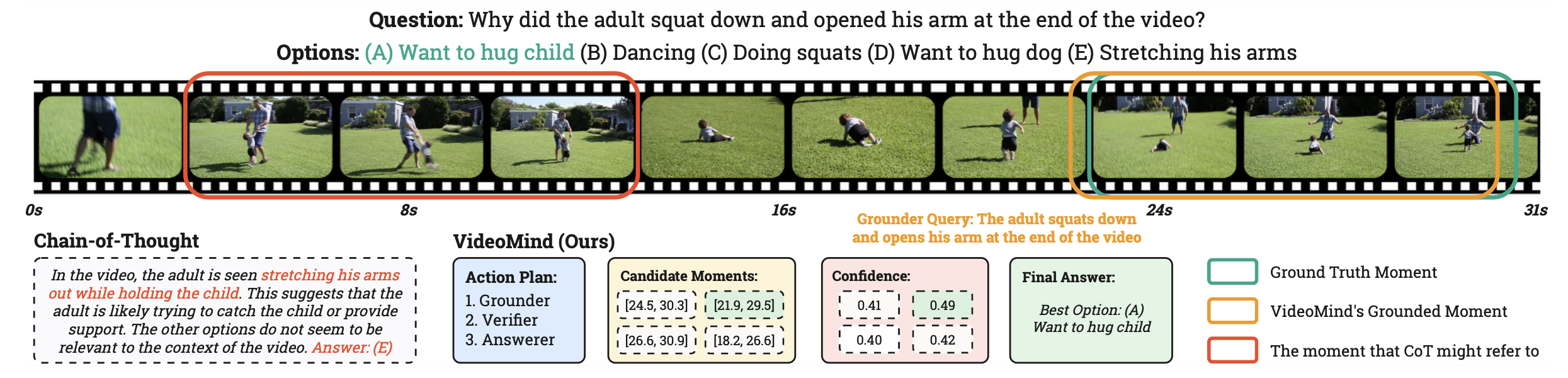
此外,Planner 具有「查询重述」能力:当原始查询缺乏足够细节时,将其转换为更描述性的版本,帮助 Grounder 更准确地定位相关时刻。这种能力尤其有利于处理模糊或抽象的问题。
Grounder
Grounder 的核心任务是「文本到视频」的时序定位:基于文本查询定位相关视频时刻(开始和结束时间戳)。为此,作者引入了 Timestamp Decoder 头来实现这一目标。
Timestamp Decoder:
该解码器通过特殊 token <REG> 触发时间戳解码过程。当模型生成此 token 时,将 <REG> token 和所有视觉 token 的最后层隐藏状态送入解码器预测时间戳 [tstart, tend]。
原始视觉 token hv ∈ ℝ(T × H × W) × DL 包含时空信息,首先通过 1D 平均池化压缩为每帧一个 token:
hv′ = AvgPool(hv) ∈ ℝT × DL
然后将压缩后的视觉特征和 <REG> 特征通过两个线性层投影到统一维度 D:
Temporal Feature Pyramid:
为增强对不同长度视频和时刻的适应性,将 ev′ 映射到四层时序特征金字塔,分别保留 1、1/2、1/4、1/8 的原始序列长度。这种多尺度设计帮助模型捕捉从短时动作到长时事件的不同粒度信息。
训练目标:
Timestamp Decoder 通过三个损失函数联合训练:
- 分类头: 帧级前景-背景分类,使用二元 focal loss:
ℒcls = −λclsα(1 − ĉi)γlog (ĉi)
- 边界回归头: 预测时间边界的 1D 偏移,使用 L1 损失:
ℒreg = λreg(|bis − b̂is|+|bie − b̂ie|)
- 对比损失: 鼓励学习更具判别性的表示:
Verifier
Verifier 用于评估 Grounder 生成的候选时刻的有效性。由于视频的复杂性,Grounder 通常生成 Top-N 预测(N=5),Verifier 通过 zoom-in 策略 选择最可靠的候选。
Recap by Zoom-in:
对每个候选时刻,将边界两侧各扩展 50%,然后裁剪并放大分辨率。这种「回溯检查」策略确保 Verifier 能够看到足够上下文来评估候选的有效性。结果视频片段与原始查询一起送给 Verifier 进行二元判断。
为增强边界感知,Verifier 引入 <SEG_START> 和 <SEG_END> 特殊 token 标记时刻的开始和结束。这些 token 帮助模型明确理解当前评估的是哪个片段。
Boolean Judgement:
Verifier 的响应是二元的 “Yes” 或 “No”。训练时基于 IoU 阈值 0.5 分配二元标签:IoU 大于 0.5 的候选标记为 “Yes”,否则为 “No”。
推理时,计算 <Yes> 和 <No> token 的似然度 Ly 和 Ln,置信度为 Sigmoid(Ly − Ln)。所有候选根据置信度重新排序,选择置信度最高的候选作为最终定位结果。
Answerer
Answerer 负责生成最终的自然语言答案。根据 Planner 的决策,Answerer 的输入有两种情况:使用 Grounder 定位的裁剪片段,或直接观看整个视频(适用于总结类问题)。
由于 Answerer 的目标与现有 LMM(Large Multimodal Model)一致,直接使用预训练模型,无需额外的微调或架构修改。这种设计大大简化了整体框架,使 VideoMind 能够快速适配新的基础模型。
Chain-of-LoRA 策略
VideoMind 的所有模块基于同一基础 LMM 构建,通过额外的 LoRA 适配器和轻量级 Timestamp Decoder(仅 Grounder 需要)增强不同角色的专用能力。
Chain-of-LoRA 的核心优势:
- 高效性: 单一 MLLM 基础 + 多个 LoRA 适配器,避免多模型部署开销
- 灵活性: 不同角色的 LoRA 适配器可动态切换,最大化角色特定能力
- 可扩展性: 新增角色仅需训练新的 LoRA 适配器,无需修改基础模型
与多任务联合训练相比,Chain-of-LoRA 能够更好地优化个体能力(时序定位性能提升约 3% mIoU)。与全分布式方法相比,Chain-of-LoRA 以四分之一的模型权重实现相近的性能。
🎯 实验结果
VideoMind 在 14 个基准测试上进行了全面评估,包括 Grounded VideoQA、Video Temporal Grounding 和 General VideoQA 等任务。实验表明,VideoMind 不仅在长视频推理任务上表现出色,在短视频任务上也展现了强大的泛化能力。
Grounded Video Question-Answering
CG-Bench(平均 27 分钟的长视频基准):
- 2B 模型超越所有对比模型,包括 InternVL2-78B 和 Claude-3.5-Sonnet
- 7B 模型超越 GPT-4o,达到竞争性整体性能
这一结果挑战了「越大越好」的假设,表明精心设计的架构和训练策略可以在更小参数量下实现更强性能。
ReXTime:
- 零样本模型超越所有零样本基线
- 性能与多个微调变体相当,同时实现更高准确率
NExT-GQA:
- 2B 模型匹配 7B SOTA 模型性能
- 7B 模型显著超越所有其他模型
Video Temporal Grounding
Charades-STA、ActivityNet-Captions:
- 零样本定位能力超越所有基于 LLM 的时序定位方法
- 与微调的时序定位专家竞争性相当
这一结果展示了 VideoMind 强大的零样本泛化能力:无需针对时序定位任务进行专门训练,即可达到接近专家模型的性能。
General Video Question-Answering
Video-MME (Long)、MLVU、LVBench:
- 长视频上表现强劲
- 时序增强设计帮助模型在回答问题前定位线索片段
这些结果验证了 VideoMind 在通用视频理解任务上的有效性,其时序定位能力为推理过程提供了可解释的视觉证据。
消融研究
各角色的贡献:
- Grounder: 通过识别视觉提示略微提升 QA 准确率,尤其对长视频有效
- Verifier: 选择最佳候选,Charades-STA 上提升 3.2 mIoU
- Planner: 通过协调角色提升准确率从 69.2 到 70.0
Chain-of-LoRA 策略的效果:
- 朴素 CoT 不能提升基础模型,需要视觉中心的测试时搜索策略
- 多任务联合训练增强基线但无法优化个体能力(定位性能约 3% mIoU)
- 全分布式方法性能最佳但需要 4 倍模型权重
- Chain-of-LoRA 以最高效方式保持顶尖性能
💡 洞察与结论
角色化工作流的有效性通过分解任务、定位时刻、验证细节、合成答案的流程实现更类人的视频推理。这种渐进式策略解决了时序锚定推理的独特挑战,使模型能够建立答案与视觉证据的直接关联。与「端到端」方法相比,显式的角色分工提供了更好的可解释性和可控性。
Chain-of-LoRA 的价值在于极简设计:单一 MLLM 基础 + LoRA 适配器,实现多角色无缝协作。确保 VideoMind 灵活适应多样化任务而无多模型开销。这种设计模式为多模态 Agent 的构建提供了一个高效且可扩展的范式。
小模型的竞争性表明:2B 模型在 CG-Bench 等长视频基准上超越 GPT-4o,挑战了「越大越好」的假设。精心设计的架构和训练策略可以在更小参数量下实现更强性能。这对资源受限的场景具有重要意义,也为模型压缩和边缘部署提供了新的思路。
时序定位的重要性体现在:视频推理的核心挑战是「在哪里」而非「是什么」。通过显式定位相关时刻并重访验证,模型能够建立答案与视觉证据的直接关联,提供可解释的推理过程。这种可解释性对于医疗、监控、教育等领域的应用至关重要。
局限性与未来方向:当前模型需要大量优化和训练数据准备。未来可探索更复杂的角色交互(如动态角色创建)、自适应的查询重述策略、以及更强大的零样本泛化能力。此外,将 VideoMind 扩展到多视频交互和实时流处理也是值得探索的方向。