Video-MTR——基于RL的长视频多轮推理框架
引言: 该研究提出 Video-MTR(Video-MTR: Reinforced Multi-Turn Reasoning for Long Video Understanding)框架,通过强化学习驱动的多轮推理机制,解决了长视频理解中「静态推理丢失关键信息」「外部 VLM 难以端到端训练」「长时依赖难以捕捉」等核心问题。Video-MTR 在 VideoMME(Long 子集 51.0% 准确率)、MLVU(测试集 48.4% 准确率)和 EgoSchema(62.4% 准确率)上超越所有开源模型,仅用 8K 训练样本即可实现 SOTA 性能。
✈️ Video-MTR 算法介绍
长视频理解面临多事件和长时依赖关系的根本挑战。现有方法普遍采用静态推理策略,通过均匀采样固定数量的帧进行处理,这种方式在处理长视频时不可避免地丢失关键信息。更严重的是,当视频包含多个相关事件分散在长时间跨度上时,静态采样无法有效捕捉这些事件间的语义关联。
为解决这一问题,部分工作采用基于 Agent 的方法,通过迭代调用外部 VLM 进行动态帧检索。然而,这种方法存在显著缺陷:外部 VLM 与主模型分离,无法进行端到端训练,导致检索策略无法与任务需求有效对齐。此外,多轮外部调用增加了系统复杂度和计算开销,难以在实际场景中部署。
Video-MTR 提出了强化多轮推理框架,核心思想是利用 MLLM 的内生能力进行迭代关键片段选择和问题理解。该方法将长视频理解建模为强化学习问题,MLLM 作为决策 Agent,通过门控双层奖励机制学习最优的检索策略。这种设计实现了端到端训练,确保检索策略与任务需求紧密耦合。
🚀 Video-MTR 算法流程
框架概述
Video-MTR 将长视频理解形式化为序列决策问题。环境提供视频帧作为状态,MLLM 作为策略网络 πθ 根据当前观察生成动作。动作空间包括两种类型:检索动作(指定要观察的帧范围)和回答动作(生成最终答案)。
训练过程遵循多轮交互循环。初始阶段,模型从长视频中均匀采样 16 帧作为初始观察。随后进入迭代阶段,模型基于当前帧生成检索决策,根据检索结果更新观察帧,并判断是否需要继续检索或直接回答。每轮最多检索 8 帧,总计最多 32 帧,这种渐进式的检索策略确保模型在有限计算预算内获取最相关的信息。
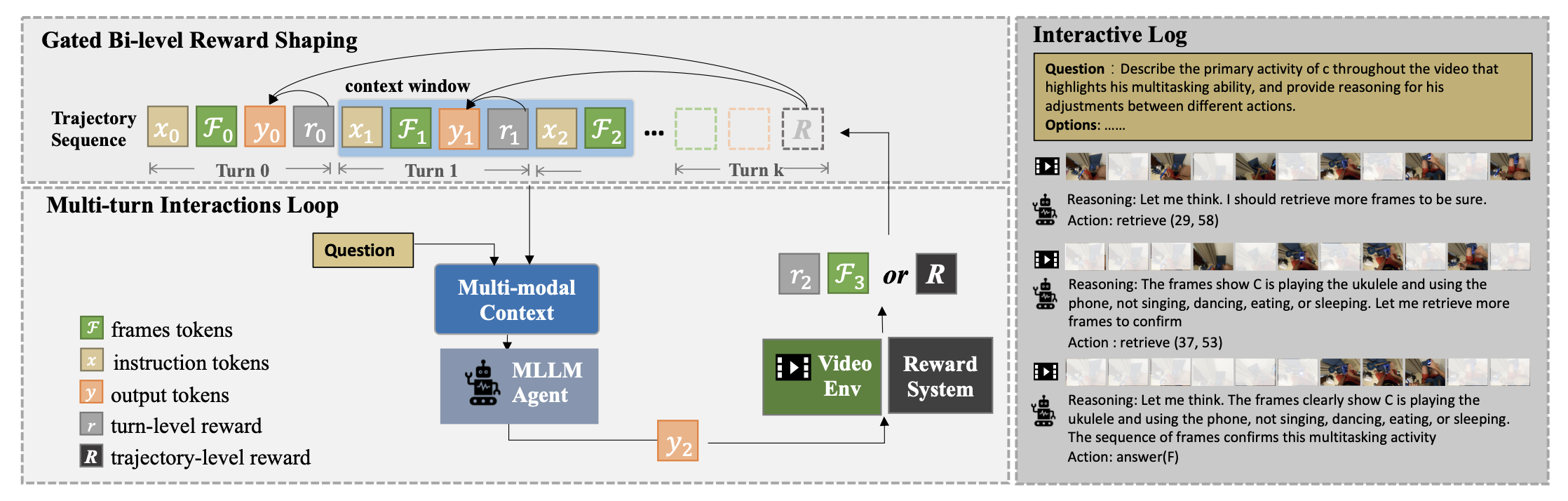
门控双层奖励机制
轨迹级奖励 (Racc) 基于最终答案的正确性给出反馈。如果模型生成的答案与标准答案一致,奖励为 1,否则为 0。这种奖励设计提供了全局反馈信号,引导整个推理轨迹向正确答案发展,避免了仅优化中间过程而偏离最终目标的问题。
轮级奖励 (Rfms) 衡量检索帧与真实时刻的相关性。具体而言,计算检索帧与标注时刻的 IoU(Intersection over Union),如果该 IoU 高于初始采样的 IoU,则给予 0.5 奖励。这种奖励鼓励模型检索更相关的视频片段,确保每一轮检索都带来信息增益。
目标门控机制 是双层奖励系统的关键设计。中间奖励(轮级奖励)以最终答案正确性为条件,只有最终正确的轨迹才能获得中间奖励。数学上,轮级奖励的实际值为 Rfms ⋅ Racc,这防止了模型通过最大化中间奖励而忽略最终正确性的「奖励黑客」行为,确保中间奖励服务于最终目标。
多轮推理流程
多轮推理采用从粗到细的信息获取策略。初始阶段,模型对长视频进行均匀采样,获得对视频内容的大致理解。这种粗粒度的全局视角帮助模型识别可能包含答案的时间区域。
迭代阶段最多进行 3 轮。在每一轮中,模型首先基于当前累积的帧生成检索决策,决策包括检索的帧数、起始位置和采样策略。环境根据决策返回新的帧,模型将这些帧与已有帧合并,更新对视频的理解。模型还输出一个决策信号,判断是否需要继续检索或已经可以生成答案。这种自适应的检索策略确保计算资源被分配到最需要的区域。
最终阶段,模型基于所有累积的帧生成最终答案。相比静态的一次性采样,多轮推理允许模型逐步聚焦关键信息,特别适合处理复杂的多细节任务。这种推理过程更符合人类理解长视频的自然方式:先获得整体印象,再逐步深入细节。
数据准备与训练
训练数据的构建是 Video-MTR 成功的关键因素之一。研究使用了两个高质量数据集:NExT-GQA 包含 5K 带时序定位的 QA 对,每个样本都标注了答案对应的视频时刻。QVHighlights 包含 3K 样本,原始格式是高光区域标注,研究使用 GPT-4o 将其转换为 QA 对格式。两个数据集总计 8K 高质量时序定位训练样本,这种精心的数据构建确保了训练信号的质量。
训练细节方面,基础模型采用 Qwen2.5-VL-7B,这是一个在视觉-语言任务上表现优异的多模态模型。训练算法采用 PPO(Proximal Policy Optimization),Actor 学习率设为 1 × 10−6,Critic 学习率为 1 × 10−5,这种不对称的设置确保策略更新保守而价值学习稳定。Batch size 为 32,训练在单服务器 8 张 NVIDIA A800-80GB GPU 上进行。
探索引导策略
强化学习训练中,Agent 容易陷入次优策略,这在复杂任务中尤为严重。Video-MTR 引入自适应探索奖励机制,鼓励早期训练中的多轮行为。该机制在训练初期提供额外的奖励加成,降低模型过早收敛到简单策略的风险。
探索奖励采用两阶段调度。第一阶段,检索率阈值设得较高,探索奖励加成较强,鼓励模型尝试多轮检索。第二阶段,阈值逐渐降低,奖励加成减弱,模型开始转向利用已学习的策略。这种探索-利用平衡确保模型既充分探索策略空间,又能在训练后期收敛到最优策略。
🎯 实验结果
主要结果
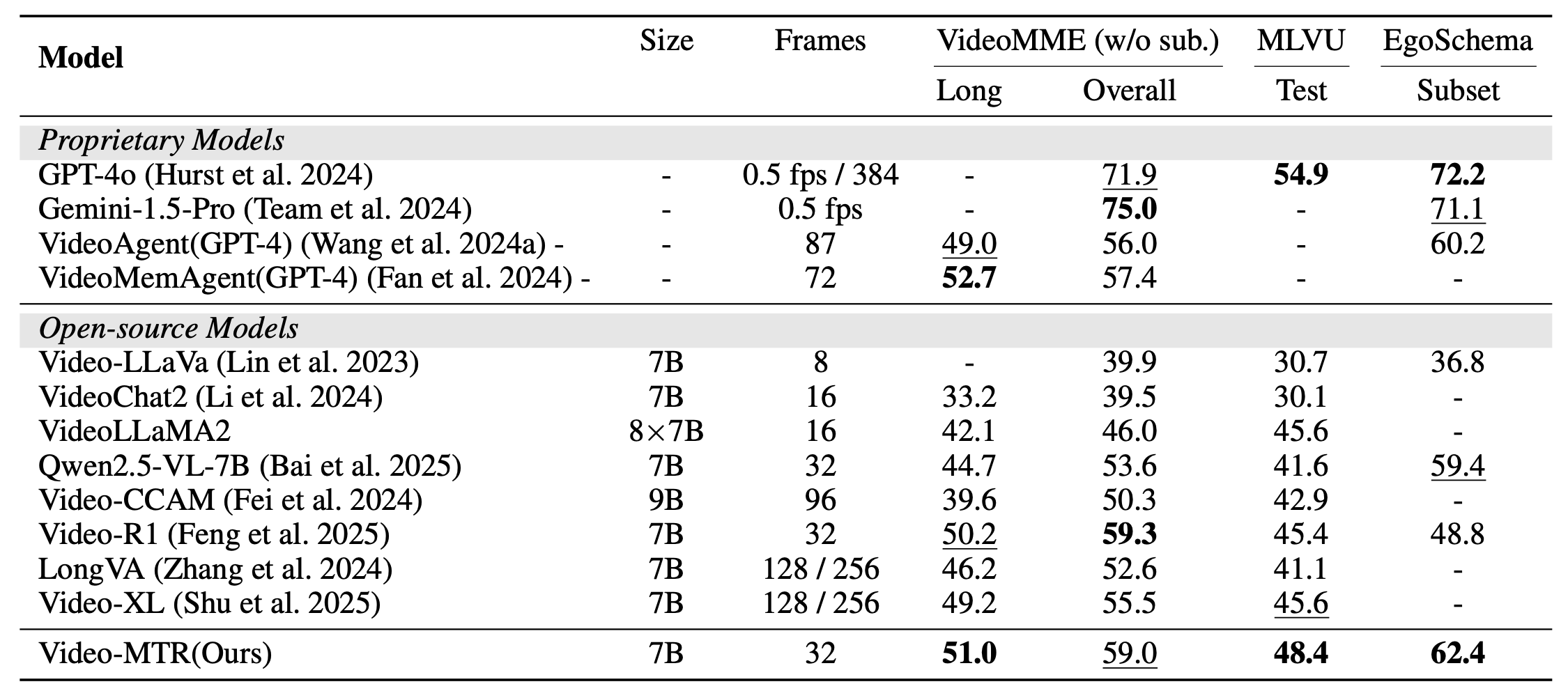
VideoMME 基准测试了 Video-MTR 在多样化视频长度上的表现。该基准包含 Short(≤ 2min)、Medium(4-15min)、Long(30-60min)三个子集,总计 2,700 QA 对。Video-MTR 在 Long 子集上达到 51.0% 准确率,超越所有开源模型。值得注意的是,Video-MTR 仅用 32 帧输入即可与 GPT-4o 和 Gemini-1.5-Pro 等专有模型竞争,展示了极高的计算效率。
MLVU 基准专注于超长视频理解,视频长度从 3 分钟到 2 小时不等,包含 11 个任务的挑战性测试集。Video-MTR 在测试集上达到 48.4% 准确率,再次超越所有开源模型。这一结果证明了框架在极端视频长度上的鲁棒性,能够处理实际应用中常见的超长视频场景。
EgoSchema 基准测试第一人称视角视频理解能力,视频时长约为 3 分钟,包含 500 个测试问题。Video-MTR 达到 62.4% 准确率,在第一人称视角任务上表现出色。这种视角常见于智能眼镜、无人机等应用场景,实验结果证明了框架在新兴领域的潜力。
数据效率
Video-MTR 的一个显著优势是数据效率。仅用 8K 训练样本即可达到 SOTA 性能,而其他方法通常需要数十万样本。这一突破具有重要的实践意义:首先,数据收集和标注是长视频理解的主要瓶颈之一,降低数据需求可以大幅减少项目成本。其次,数据效率表明强化学习框架能够从有限样本中有效学习,而非依赖大规模数据驱动的模式匹配。
数据效率的实现归功于多个设计。门控双层奖励机制提供了清晰的学习信号,探索引导策略加速了策略收敛,精心构建的高质量训练数据确保了每个样本都有丰富信息。这些设计共同构成了一个高效的学习系统。
消融研究
多轮推理的贡献通过消融实验得到验证。当限制为单轮推理时,单细节任务准确率下降 7.5%,多细节任务下降 8.1%。这一结果清晰地表明,多轮推理对复杂任务带来显著收益。随着任务复杂度增加,模型需要从视频中提取更多信息,多轮推理提供的渐进式信息获取策略变得至关重要。
双层奖励机制的有效性同样得到验证。去除双层奖励后,准确率下降 4%。这一结果说明双层奖励对有效的时序定位至关重要。仅依赖最终答案奖励难以指导模型学习良好的检索策略,而仅依赖轮级奖励容易导致奖励黑客行为,双层机制实现了两者的平衡。
目标门控机制的消融展示了其防止奖励黑客的作用。当去除目标门控时,模型倾向于通过最大化中间奖励(如检索到高 IoU 的帧)而忽略最终答案正确性。这种结果表明,在多步决策任务中,确保中间奖励服务于最终目标是设计稳定学习系统的关键原则。
💡 洞察与结论
强化学习的价值体现在将长视频理解建模为序列决策问题。传统方法依赖预定义的静态采样策略,无法适应不同任务的多样性需求。Video-MTR 通过奖励信号引导模型学习最优的检索策略,实现了任务驱动的自适应帧选择。这种端到端训练确保检索策略与任务需求紧密耦合,而非依赖人工设计的启发式规则。
多轮推理的有效性通过迭代片段选择和问题理解实现。相比静态的一次性采样,多轮推理允许模型逐步聚焦关键信息,特别适合处理复杂的多细节任务。这种从粗到细的推理过程更符合人类理解长视频的自然方式,也为模型提供了更多的推理步骤,有助于捕捉长时依赖关系。
数据效率的突破表明精心设计的强化学习框架可以用 8K 样本达到 SOTA,而其他方法需要数十万样本。这对数据稀缺的领域具有重要启示:当样本数量有限时,算法设计的质量比数据规模更为关键。这一发现也降低了长视频理解的训练门槛,使更多研究团队能够参与这一领域的研究。
门控奖励机制的设计解决了强化学习中常见的「奖励黑客」问题。在多步决策任务中,中间奖励如果不受约束,模型可能通过操纵中间状态来最大化奖励而忽略最终目标。Video-MTR 的目标门控机制确保中间奖励以最终答案正确性为条件,这一设计原则可推广到其他多步决策任务,如机器人控制、规划等。
局限性与未来方向:当前框架依赖预定义的检索和回答动作,限制了动作空间的灵活性。未来可探索更灵活的动作空间,如自由形式的检索查询和自适应的轮数调整策略。泛化能力是另一个值得探索的方向,当前模型在未见过的视频类型上的表现仍有提升空间。此外,将框架扩展到多模态输入(如音频、文本)也是值得探索的方向,音频线索在长视频理解中往往包含重要的上下文信息。