Seed1.5-VL——技术报告详解
引言: Seed1.5-VL 是字节跳动 Seed 团队推出的视觉语言基础模型,由 532M 参数的视觉编码器和 20B 激活参数的 MoE LLM 组成。在 60 个公开基准上取得 38 个 SOTA,包括 21/34 视觉语言基准、14/19 视频基准和 3/7 GUI 智能体任务。在 GUI 控制和游戏玩法等智能体任务上超越 OpenAI CUA 和 Claude 3.7 Sonnet。
✈️ 引言
视觉语言模型(VLM)已成为实现通用人工智能感知、推理和行动的基础范式。通过在统一模型内对齐视觉和文本模态,VLM 在多模态推理、图像编辑、GUI 智能体、自动驾驶和机器人等领域快速推进研究前沿。
然而,尽管取得实质性进展,当前 VLM 在需要 3D 空间理解、对象计数、想象性视觉推理和交互式游戏等任务上仍未达到人类水平。这些局限性凸显了 VLM 开发的固有挑战:VLM 缺乏足够丰富多样的视觉语言标注,多模态数据的异构性增加了训练和推理的复杂性。
Seed1.5-VL 通过多样化数据合成流水线解决高质量标注稀缺问题,针对 OCR、视觉定位、计数、视频理解和长尾知识等关键能力进行预训练,以及视觉谜题和游戏的后训练。模型在万亿级多模态 token 上预训练,后训练阶段整合人类反馈和可验证奖励信号增强通用推理能力。
阅读提示: 本文按原文结构依次介绍模型架构、预训练数据与训练配方、后训练流程、训练基础设施和全面评估结果。Seed1.5-VL 在 MathVista(85.6)、DocVQA(96.9)、CountBench(93.7)等基准上取得 SOTA。
🏗️ 模型架构
Seed1.5-VL 的架构包含三个组件:视觉编码器、MLP 适配器和大语言模型(LLM)。视觉编码器原生支持动态图像分辨率,采用 2D RoPE 进行位置编码;MLP 适配器通过
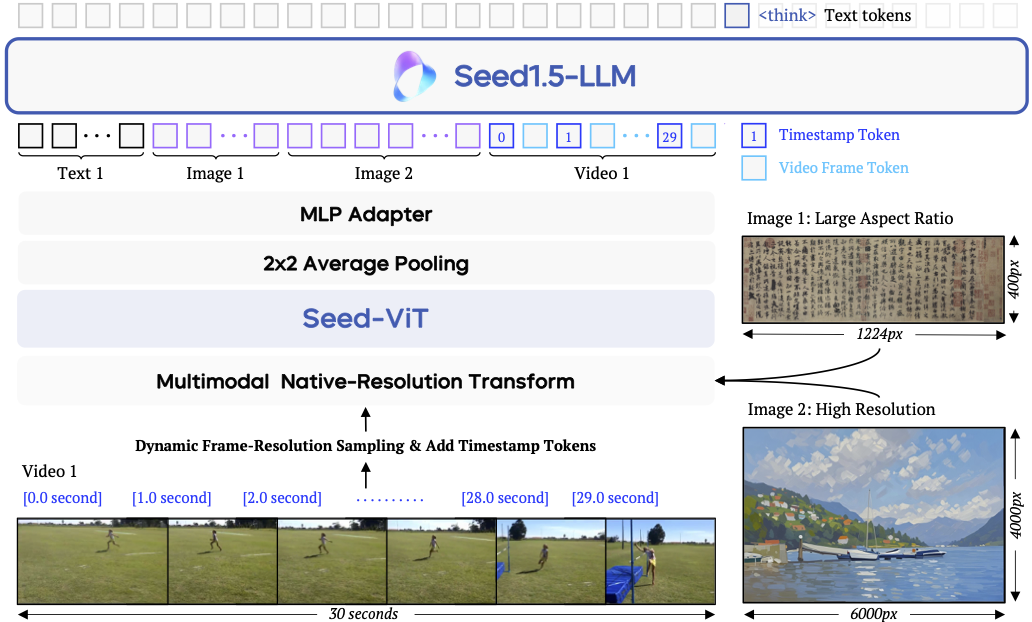
视觉编码器
许多当代 VLM 集成为固定输入分辨率设计的预训练视觉编码器,这会在处理高分辨率图像、视频或需要精细细节的任务(如 OCR)时丢失细粒度视觉信息。Seed1.5-VL 开发了 Seed-ViT,专门为原生分辨率特征提取设计的视觉编码器。
Seed-ViT 基于 Vision Transformer 架构,包含 532M 参数。在零样本分类基准上,Seed-ViT 达到与参数量显著更大的模型(如 6B 参数的 InternVL-C)相当的性能。
架构超参数:
| Patch Size | Position Embed | Head Dim | Num Heads | Embed Dim | MLP Ratio | Depth |
|---|---|---|---|---|---|---|
| 14 | 2D RoPE | 64 | 20 | 1280 | 4.0 | 27 |
输入图像通过双线性插值调整分辨率至最接近的
ViT 预训练
Seed-ViT 在集成到 VLM 之前经历独立的预训练流程,遵循三大准则:
- ViT 预训练提升训练效率:无编码器 VLM 训练效率仍不足
- 早期整合原生分辨率建模:架构在 ViT 预训练和 VLM 阶段保持一致,避免性能下降
- 全面数据利用:预训练阶段利用 VLM 训练的全部数据类型
ViT 预训练分为三个阶段:
| 阶段 | 方法 | 数据规模 | 目标 |
|---|---|---|---|
| MIM with 2D RoPE | 掩码图像建模 | 大规模图像 | 视觉几何和结构感知 |
| Native-Resolution CL | 对比学习 | 图文对 | 图像-文本对齐 |
| Omni-modal Pre-training | MiCo 框架 | 视频+音频 | 统一全模态表示 |
MIM with 2D RoPE:使用 EVA02-CLIP-E 作为教师模型,随机掩码 75% 图像 patch,通过余弦相似度损失重建 CLIP 特征。学生模型使用 2D RoPE,教师模型使用可学习位置嵌入,这种差异不影响性能,反而赋予学生模型鲁棒的原生动态分辨率识别能力。
原生分辨率对比学习:使用 MIM 训练的学生模型初始化视觉编码器,文本编码器从 EVA-02-CLIP-E 初始化。通过注意力池化将 patch 特征聚合为 1280 维图像嵌入,联合优化 SigLIP 损失和 SuperClass 损失。
全模态预训练:采用 MiCo 框架构建对齐元组,包含视频帧、音频、视觉字幕和音频字幕。ViT 同时编码视频帧和音频,尽管仅消耗 4.8% 的 token 预算,但显著增强图像和视频理解能力。
视频编码
有效编码视频仍是核心挑战。模型解释时间序列、适应不同帧率和感知绝对时间的能力对理解动态视觉内容至关重要。Seed1.5-VL 引入动态帧分辨率采样策略,联合优化时间和空间维度。
时间维度:根据内容复杂度和任务要求动态调整帧采样频率:
- 默认:1 FPS(通用视频理解)
- 详细时间信息:2 FPS(动作理解任务)
- 计数/运动追踪:5 FPS
每帧前添加时间戳 token(如 [1.5 second])增强时间感知。
空间维度:动态调整每帧分辨率,在最大 81,920 token/视频预算内,提供六级分辨率选择:{640, 512, 384, 256, 160, 128}。视频超长时触发回退机制,通过均匀采样减少帧数确保完整表示。
📊 预训练
预训练数据
Seed1.5-VL 预训练语料包含 3 万亿多样化高质量 token,按目标能力分类组织。
通用图文对与知识数据:网络图文对数据规模空前但存在噪声和类别不平衡。作者通过 CLIP 分数过滤、图像/文本标准过滤、去重和 URL/域名过滤等手段清洗数据。针对长尾分布问题,使用 VLM 自动标注语义域和命名实体,识别低频视觉知识,对表示不足的域进行上采样重平衡。
OCR 数据:构建超过 10 亿样本的 OCR 训练集,覆盖文档、场景文本、表格、图表和流程图。文档数据从多来源收集并提取内容和布局;合成超过 2 亿文本密集图像,使用 SynthDog 和 LaTeX,应用模糊、摩尔纹和扭曲增强;图表数据超过 1 亿样本,结合开源数据集和 LLM 生成流水线;表格数据超过 5000 万图像,渲染 HTML、LaTeX 和 Markdown 格式。
视觉定位与计数:采用边界框和中心点两种定位表示,扩展到对象计数。使用 Objects365、OpenImages、RefCOCO/+/g 等开源数据,通过 VLM 检查过滤低质量样本,构建通用 2D 定位、空间关系问答、视觉提示问答等多任务数据(约 4800 万样本、410 亿 token)。自动标注流水线带来约 2 亿样本、2000 亿 token。
3D 空间理解:构建相对深度排序、绝对深度估计和 3D 定位三类数据。使用 DepthAnything V2 推断 200 万互联网图像的对象深度关系(32 亿 token);从公开数据集提取绝对深度(1800 万指令对、280 亿 token);3D 定位数据(77 万指令对、13 亿 token)。
视频数据:分为通用视频理解(字幕、问答、动作识别/定位、多图像理解)、时间定位和流式视频三类。流式视频数据包含交错字幕/问答、主动推理和实时解说,增强实时视频理解能力。
STEM 数据:收集 320 万高质量教育定位样本(数学/物理/化学/生物)、1000 万结构化表格、450 万化学结构图、150 万坐标系图、K12 标注数据(10 万人工标注、100 万 VQA、100 万机器字幕)和超过 1 亿 K12 练习题。
GUI 数据:来自 UI-TARS,覆盖 Web、App 和桌面环境。截图配对结构化元数据(元素类型、边界框、文本、深度),构建感知(元素描述、密集字幕、状态转换字幕)、定位(从文本描述预测坐标)和推理(多步任务轨迹)任务。
训练配方
Seed1.5-VL 采用后置适配方法,LLM 从约 20B 激活参数的内部预训练 MoE 模型初始化。VLM 预训练分为三阶段:
| 阶段 | Token 预算 | 序列长度 | 可训练组件 | 批大小 | 最大学习率 |
|---|---|---|---|---|---|
| Stage 0 | 16B | 32,768 | MLP 适配器 | 8.4M | |
| Stage 1 | 3T | 32,768 | 全部 | 71M | |
| Stage 2 | 240B | 131,072 | 全部 | 71M |
- Stage 0:仅训练 MLP 适配器,视觉编码器和 LLM 冻结。跳过此阶段会导致损失略高和性能下降。
- Stage 1:所有参数可训练,知识积累和视觉定位/OCR 能力学习。添加 5% 纯文本 token 维持语言能力,少量指令遵循数据使评估更可靠。
- Stage 2:更平衡的数据混合,新增视频理解、编码和 3D 空间理解域。序列长度扩展到 131,072 以建模长依赖。
训练策略差异:作者尝试了 Stage 0 同时训练 MLP 适配器和视觉编码器的方案(类似 Qwen2-VL),但实验表明本文方案性能更优。假设是视觉编码器试图补偿冻结 LLM 的潜在缺陷,可能损害其感知能力。
缩放定律
VLM 预训练与 LLM 标准实践(随机初始化所有参数)有根本差异。基于预训练组件(视觉编码器、MLP 适配器、LLM),固定模型架构,损失主要依赖训练数据规模:
观察发现,特定数据子类别的训练损失与下游任务性能呈近似对数线性关系。例如:
这表明可以通过监控训练损失预测下游任务性能,指导数据收集和训练策略。
🚀 后训练
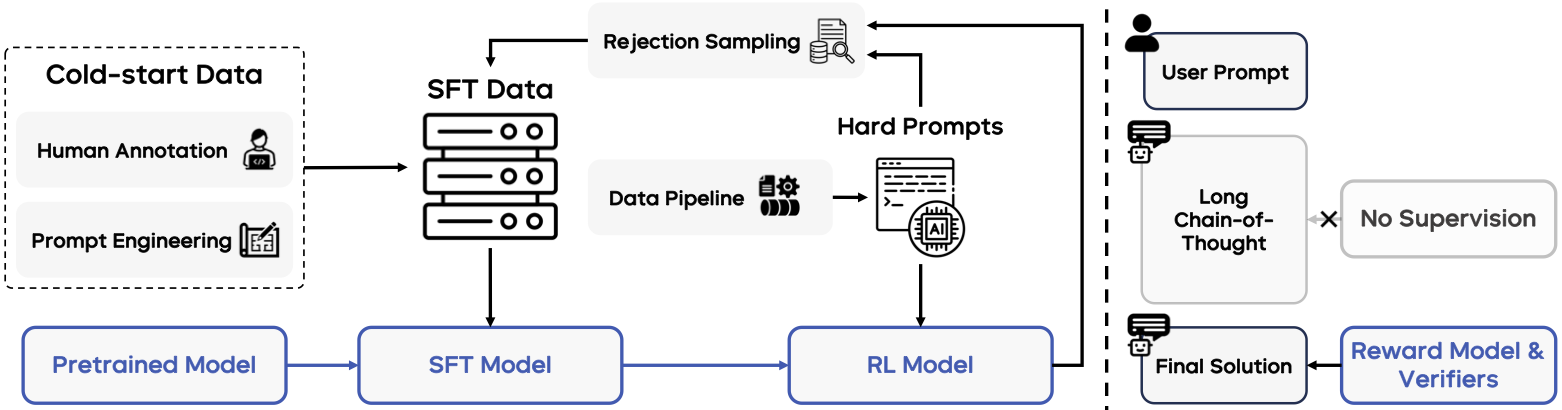
后训练将基座模型转化为具有强推理、编码和智能体能力的助手。采用渐进对齐策略:SFT 引入交错思考模式,专用 RL 阶段处理推理和智能体任务,通用 RL 阶段实现人类风格对齐,最后通过策略内跨阶段蒸馏减轻能力遗忘。
监督微调
SFT 数据覆盖三大类别:
- 通用聊天:问答、写作、角色扮演、翻译、多轮对话、长上下文交互
- 推理:数学、编程、科学推理
- 编码与智能体:前端/后端代码、工具调用、编码智能体、搜索智能体、通用智能体
长链思维(LongCoT)数据:主要来自 STEM 编程和数学问题。使用 LLM 翻译公开可用推理数据,生成中英双语版本的详细推理过程。任务领域包括多步几何推理、代码生成与调试、复杂游戏策略、长视程规划和常识推理。
评估导向数据:整合内部评估集到 SFT 流水线,包含复杂推理问题(数学竞赛、高难度 STEM)、代码挑战(竞技编程、工程任务)和智能体任务(复杂导航、GUI 操作)。
混合强化学习
后训练采用混合 RL 框架,结合人类反馈(RLHF)和可验证奖励信号(RLVF)。
可验证任务设计:定义三类可验证任务:
- 编程任务:通过执行测试用例验证正确性
- 数学任务:与标准答案精确匹配验证
- 视觉定位任务:与真实坐标的空间重叠验证
混合奖励:训练提示分为通用提示和可验证提示,分别使用奖励模型和验证器奖励。通用提示采样 1 次,可验证提示采样 4-8 次以支持充分探索。
共享 Critic:单一 critic 模型架构估计两种奖励源的价值函数。奖励模型输出归一化到 [0,1],验证器结果显式缩放到相同范围。
KL 系数:通用提示使用
LongCoT RL 的涌现能力:尽管仅在 LongCoT 响应上训练,模型在无需扩展推理的常规响应上也观察到显著改进。这表明推理能力的训练可以泛化到标准任务。
拒绝采样微调迭代更新
采用迭代训练策略增强模型。初始 LongCoT SFT 模型通过少量标注样本上下文提示生成。观察到更强的冷启动 SFT 自然导向更强的 LongCoT RL 最终模型,采用拒绝采样微调获取改进起点。
每轮 LongCoT RL 发布后,收集额外挑战性提示,用最新 RL 模型评估,正确回答的响应纳入下一轮 SFT 数据。使用 RL 阶段相同验证器确认正确性,手动正则过滤移除无限重复、过度思考等不良模式。当前版本已迭代 4 轮,持续改进。
🏭 训练基础设施
大规模预训练
预训练阶段共消耗 130 万 GPU 小时(归一化到 H800)。开发了多项训练优化:混合并行、负载均衡、并行感知数据加载、容错训练。
混合并行:视觉编码器采用 ZeRO 数据并行,LLM 采用标准 4D 并行(专家并行 + 流水线并行 + ZeRO-1 数据并行 + 上下文并行)。分离编码器和 LLM 的并行策略以提高效率和简洁性。
负载均衡:视觉样本包含不同数量图像,导致 GPU 计算不平衡。采用贪心算法重分布视觉数据:按计算强度降序排列图像,依次分配给当前计算强度最低的 GPU。实验设置组大小为 128-256 GPU。
并行感知数据加载:非数据并行组的 GPU 消费相同训练样本。仅一个 GPU 加载数据,通过广播传输元数据。每个 GPU 仅处理加载图像数据的一部分,减少 PCIe 流量。使用预取器确保 IO 和计算完全重叠。
后训练框架
在 verl-based 框架上实施混合 RL,结合单控制器管理 RL 间数据流和多控制器管理 RL 内数据和模型并行。验证器部署为进程服务隔离潜在故障。
Actor 和 critic 训练采用 3D 并行,rollout 生成和奖励/参考模型推理使用副本(各配置张量并行)。RL 阶段消耗 6 万 GPU 小时,奖励模型训练消耗 2.4 万 GPU 小时。
🎯 评估结果
视觉编码器评估
Seed-ViT 在零样本分类基准上达到 82.5% 平均准确率,与 InternVL-C-6B(6B 参数)相当,而参数仅为其 9%。与 30 倍参数量的 EVA-CLIP-18B 相比,在多数 ImageNet 变体上准确率相当,在 ObjectNet 和 ImageNet-A 上表现更优,表明更强的真实世界变化鲁棒性。
视觉任务评估
Seed1.5-VL 在 60 个公开基准上评估,取得 38 个 SOTA。
多模态推理:
| 基准 | Seed1.5-VL (thinking) | Seed1.5-VL | Gemini 2.5 Pro | GPT-4o |
|---|---|---|---|---|
| MMMU | 77.9 | 73.6 | 81.7 | 70.7 |
| MathVista | 85.6 | 83.0 | 82.7 | 63.8 |
| VLM are Blind | 92.1 | 90.8 | 84.3 | 50.4 |
| VisuLogic | 35.0 | 33.0 | 31.0 | 26.3 |
文档与图表理解:
| 基准 | Seed1.5-VL (thinking) | Seed1.5-VL | Gemini 2.5 Pro | Qwen 2.5-VL 72B |
|---|---|---|---|---|
| TextVQA | 81.8 | 84.2 | 76.8 | 83.5 |
| DocVQA | 96.9 | 96.7 | 94.0 | 96.4 |
| InfographicVQA | 91.2 | 89.3 | 84.3 | 87.3 |
| ChartQA | 89.1 | 87.4 | 83.3 | 89.5 |
定位与计数:Seed1.5-VL 在所有定位和计数基准上取得 SOTA:
| 基准 | Seed1.5-VL (thinking) | Seed1.5-VL | Gemini 2.5 Pro | Qwen 2.5-VL 72B |
|---|---|---|---|---|
| BLINK | 72.1 | 70.2 | 70.6 | 64.4 |
| RefCOCO-avg | 91.3 | 91.6 | 74.6 | 90.3 |
| CountBench | 93.7 | 93.5 | 91.0 | 93.6 |
| FSC-147 ↓ | 17.9 | 18.6 | 24.5 | 28.6 |
3D 空间理解:在深度估计和 3D 定位上大幅超越前代 VLM:
| 基准 | Seed1.5-VL (thinking) | Seed1.5-VL | Gemini 2.5 Pro | Qwen 2.5-VL 72B |
|---|---|---|---|---|
| DA-2K | 91.7 | 91.9 | 73.0 | 69.6 |
| NYU-Depth V2 ↓ | 13.6 | 11.6 | 27.5 | 35.5 |
| All-Angles Bench | 58.6 | 59.0 | 53.4 | 55.7 |
定位与计数 SOTA 满堂红:Seed1.5-VL 在 BLINK、LVIS-MG、VisualWebBench、RefCOCO-avg、CountBench、FSC-147 六个定位/计数基准上全部取得第一。在 LVIS-MG 上达到 73.8 F1,超越传统检测器 Grounding DINO-L(54.4)。
视频任务评估
Seed1.5-VL 在 19 个视频基准上取得 14 个 SOTA:
| 能力维度 | 基准 | Seed1.5-VL | Prior SOTA |
|---|---|---|---|
| 短视频 | MotionBench | 68.4 | 62.8 (GLM-4V) |
| 短视频 | TVBench | 63.6 | 62.6 (Gemini 2.5 Pro) |
| 短视频 | TempCompass | 83.7 | 75.8 (Gemini 2.5 Pro) |
| 长视频 | MLVU | 82.1 | 81.2 (Gemini 2.5 Pro) |
| 流式视频 | OVBench | 60.0 | 54.9 (PMB) |
| 流式视频 | StreamBench | 72.8 | 68.7 (GPT-4o) |
| 视频定位 | Charades-STA | 64.0 | 64.7 (Seed1.5-VL) |
| 视频定位 | TACoS | 49.6 | 42.4 (SG-DETR) |
智能体评估
GUI 智能体:
| 基准 | Seed1.5-VL | Claude 3.7 Sonnet | OpenAI CUA |
|---|---|---|---|
| ScreenSpot Pro | 60.9 | 56.4 | 57.6 |
| ScreenSpot v2 | 95.2 | 94.4 | 90.8 |
| OSWorld | 36.7 | 28.0 | 38.1 |
| WebVoyager | 87.2 | 82.6 | 82.4 |
| AndroidWorld | 62.1 | 46.6 | 38.5 |
GUI 智能体领先:Seed1.5-VL 在 WebVoyager(87.2%)和 Online-Mind2Web(76.4%)上超越 OpenAI CUA 和 Claude 3.7 Sonnet,在 AndroidWorld(62.1%)上大幅领先。在基础 VLM 中 GUI 能力显著领先。
游戏智能体:在 14 个 Poki.com 游戏上评估,Seed1.5-VL 在 2048(870.6 vs 611.2)、Hex-Frvr(1414.0 vs 651.6)等游戏上大幅超越 OpenAI CUA 和 Claude 3.7 Sonnet。长视程游戏玩法特别适合评估推理时扩展行为,Seed1.5-VL 展现出随交互轮数增加保持更高性能的强扩展性。
模型局限性
尽管在多个基准上表现优异,Seed1.5-VL 在以下方面存在局限:
精细视觉感知:对象不规则排列、颜色相似或部分遮挡时计数困难;识别图像间细微差异有时出错;复杂空间关系解读不准确
高级推理:在人类简单的任务(如华容道、迷宫导航)上表现欠佳,需要探索视觉 Chain-of-Thought 等技术
组合搜索:需要组合搜索的推理任务对现有 VLM 架构仍是挑战,代码使用和外部工具集成是未来方向
3D 空间推理:3D 对象操作和投影推理任务仍有困难,图像生成能力可能是解决方案
幻觉:当视觉输入与语言模型先验知识冲突时,模型倾向于优先考虑先验知识
💡 结论
Seed1.5-VL 是字节跳动 Seed 团队推出的视觉语言基础模型,通过 532M 参数视觉编码器和 20B 激活参数 MoE LLM 的紧凑架构,在 60 个公开基准上取得 38 个 SOTA。模型在定位、计数、3D 空间理解、文档理解(TextVQA、DocVQA、InfographicVQA)和部分推理任务(MathVista、VLM are Blind)上建立领先地位。
核心贡献包括:
- Seed-ViT 原生分辨率编码器:三阶段预训练流程实现高效视觉感知
- 动态帧分辨率采样:联合优化视频时空维度
- 多样化数据合成流水线:针对 OCR、定位、计数、3D 空间等关键能力
- 混合 RL 后训练:结合人类反馈和可验证奖励信号
通过开源模型权重,团队希望推动社区向高效智能通用智能体系统迈进,加速实现通用人工智能的愿景。