SAPO——软自适应策略优化算法
引言: 该研究提出 SAPO(Soft Adaptive Policy Optimization)算法,通过引入温度控制的软门控函数替代传统的硬裁剪机制,解决了 GRPO 和 GSPO 中存在的「梯度不连续」「正负样本不对称处理」等问题。SAPO 结合了 GSPO 的序列级一致性优势和 GRPO 的 token 级自适应能力,在 Qwen3 和 Qwen3-VL 的训练中取得了更优的性能和稳定性。
✈️ SAPO 算法介绍
GRPO 和 GSPO 都采用硬裁剪(Hard Clipping)机制来约束策略更新幅度,但这种设计存在根本性问题。硬裁剪在边界处产生梯度不连续,导致训练信号突变;同时,对正样本(优势为正)和负样本(优势为负)采用相同的裁剪阈值,忽略了两者在优化动态上的本质差异。
从优化稳定性角度分析,负样本比正样本更需要谨慎处理。当模型试图降低某个 token 的概率时,如果降低幅度过大,可能导致该 token 的 likelihood 接近零,引发数值不稳定甚至模型崩溃。相比之下,提升正样本概率的风险较小,因为概率上限为 1,不会出现发散问题。然而,传统的对称裁剪无法体现这种差异。
为此,作者提出 SAPO(Soft Adaptive Policy Optimization)算法,核心创新是用温度控制的软门控函数替代硬裁剪。软门控提供平滑的梯度过渡,消除边界处的不连续性;通过非对称温度设计,对正负样本施加不同强度的约束,在保持探索能力的同时确保训练稳定性。SAPO 在理论上融合了 GSPO 的序列级思想和 GRPO 的 token 级自适应性,在实践中已成功应用于 Qwen3 系列模型的训练。
🚀 SAPO 算法流程
SAPO 的目标函数与 GRPO 形式相似,关键区别在于将硬裁剪替换为软门控:
其中 ri, t(θ) 是 token 级重要性采样比率,Âi 是组级优势估计,fi, t(⋅) 是软门控函数。与硬裁剪的本质区别在于:fi, t 是连续可微的,且其形状由温度参数自适应控制。
软门控函数设计
SAPO 的软门控函数定义为:
其中 σ(⋅) 是 sigmoid 函数,τi, t 是温度参数。这个设计有三个关键特性。
首先,以 1 为中心:当 x = 1(即新旧策略相同)时,
对软门控函数求导,可得梯度权重:
wi, t(θ) = 4pi, t(θ)(1 − pi, t(θ))
其中 pi, t(θ) = σ(τi, t(ri, t(θ) − 1))。这个权重具有自适应特性:当策略变化处于中间区域时权重最大,当策略变化过大或过小时权重自动衰减,实现了对异常更新的自然抑制。
非对称温度设计
SAPO 的核心创新之一是非对称温度:对正样本和负样本使用不同的温度参数。
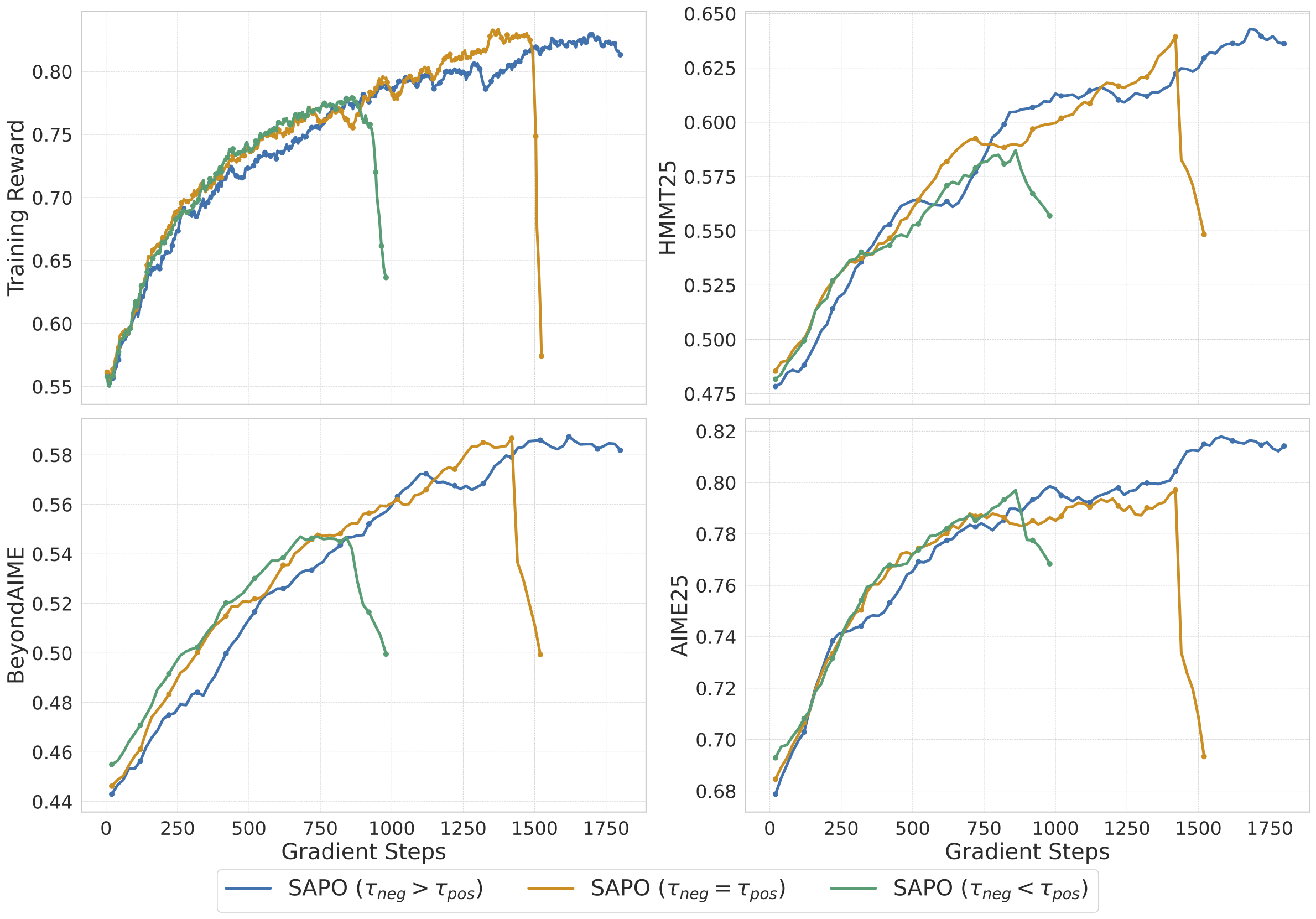
实验中采用 τpos = 1.0,τneg = 1.05,即负样本使用更大的温度。更大的温度意味着更平缓的门控曲线,对策略变化的容忍度更高,约束更宽松。
这一设计的动机在于:降低负样本概率需要更谨慎的控制。如果对负样本施加过强约束(小温度),可能导致概率下降过快而引发数值问题;但如果约束过弱(大温度),又无法有效抑制不良行为。τneg = 1.05 是在稳定性和有效性之间的平衡点。消融实验表明,这个看似微小的差异(0.05)对训练稳定性有显著影响。
与 GSPO 和 GRPO 的关系
SAPO 可以被理解为 GSPO 和 GRPO 思想的融合。
从 GSPO 继承的特性包括:组级优势估计 Âi(而非 token 级),序列内 token 共享相同的优势值,保持了序列级的优化一致性。从 GRPO 继承的特性包括:token 级重要性采样比率 ri, t(θ),保留了对每个 token 的细粒度控制能力。
SAPO 的独特贡献是软门控机制:既不像 GRPO 那样在 token 级别进行硬裁剪导致梯度不连续,也不像 GSPO 那样完全放弃 token 级自适应性。软门控提供了一种中间方案,在保持梯度平滑的同时实现自适应约束。
🎯 训练细节与实验结果
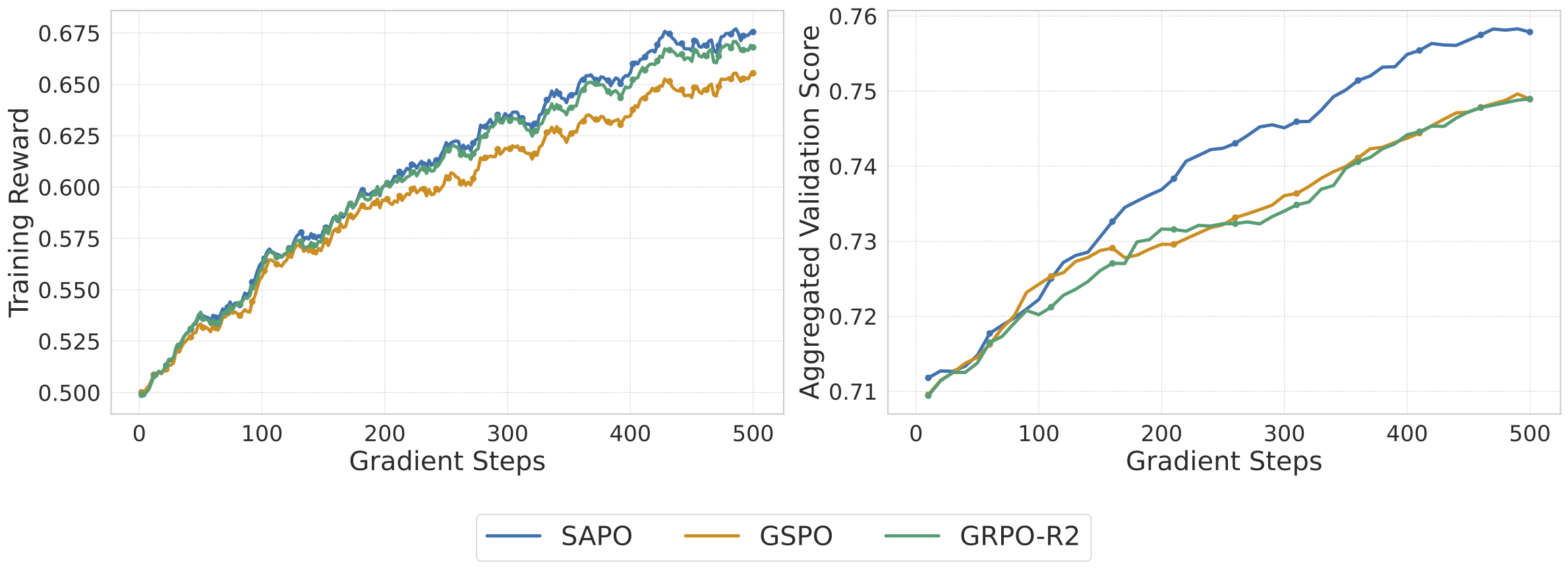
作者以 Qwen3-30B-A3B 模型为基础进行实验,评估基准包括 AIME’24 和 LiveCodeBench。训练采用标准的 RL 设置,软门控温度参数设为 τpos = 1.0,τneg = 1.05。
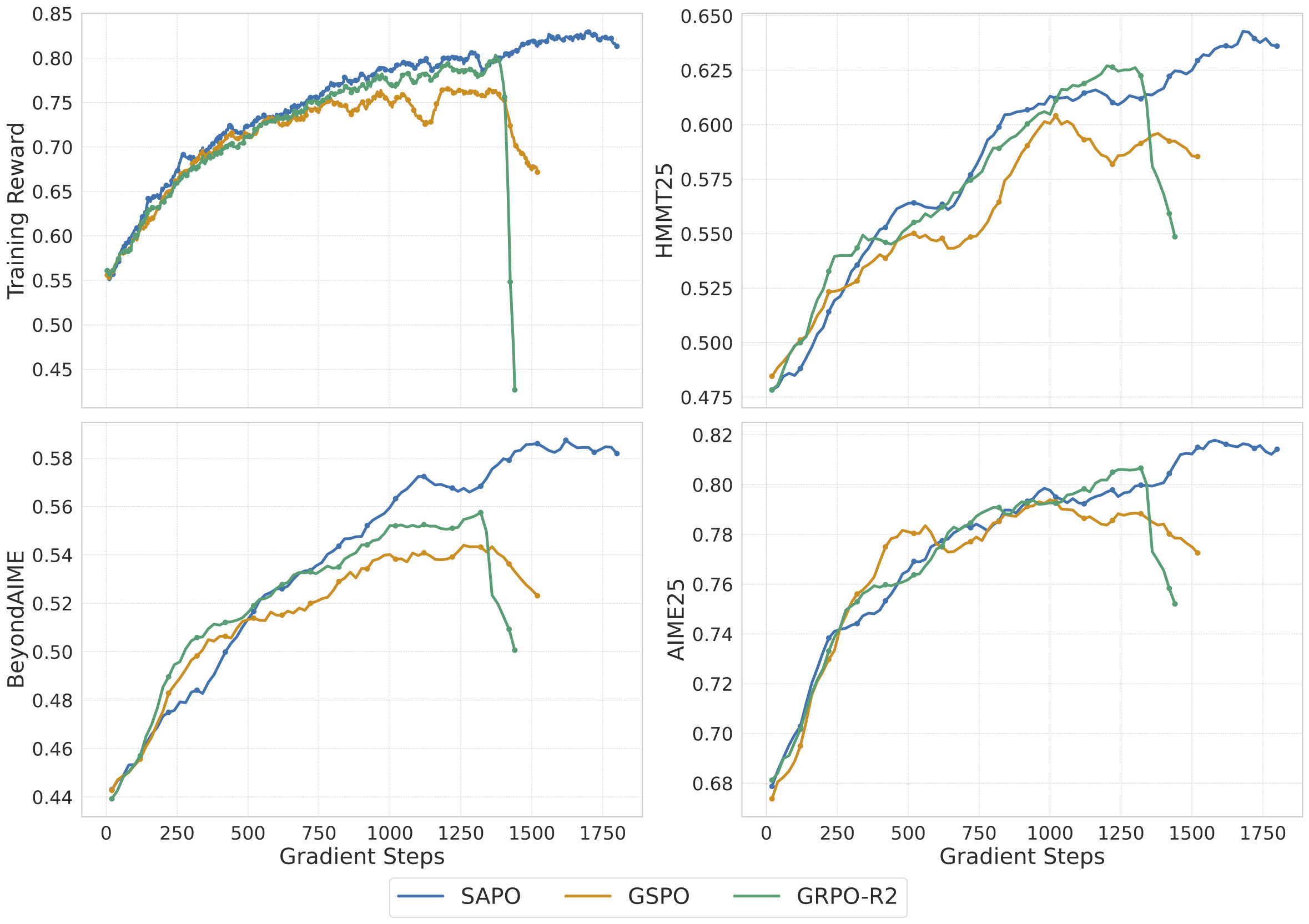
温度消融实验揭示了几个关键发现。首先,非对称温度优于对称温度:使用相同温度处理正负样本会导致性能下降,验证了非对称设计的必要性。其次,负样本温度敏感:τneg 的微小变化对训练稳定性影响显著,过小会导致数值问题,过大会削弱对负样本的抑制效果。最后,正样本温度相对鲁棒:τpos 在较大范围内变化对性能影响较小。
在 Qwen3-VL(视觉语言模型)的训练中,SAPO 同样表现出色。视觉语言任务的奖励信号通常更稀疏、噪声更大,软门控的平滑特性有效缓解了这些问题。相比硬裁剪方法,SAPO 在多模态场景下展现出更好的训练稳定性和最终性能。
💡 洞察与结论
软门控的优势在于提供了梯度的连续性保证。硬裁剪在边界处产生梯度突变,可能导致优化过程中的震荡;软门控通过 sigmoid 函数实现平滑过渡,使训练动态更加可预测。这一改进看似简单,却从根本上改善了 RL 训练的稳定性。
非对称设计的重要性体现了对正负样本不同优化动态的深刻理解。提升正样本概率和降低负样本概率是两个本质不同的操作,前者受限于概率上限 1,后者可能导致概率趋近于 0 而引发数值问题。非对称温度正是对这种差异的直接回应。
方法论的演进从 GRPO 到 GSPO 再到 SAPO,体现了 LLM RL 领域对优化粒度和约束机制的持续探索。GRPO 发现了组内相对优势估计的价值,GSPO 揭示了序列级优化的理论优势,SAPO 则进一步引入了软约束和自适应机制。每一步演进都解决了前一方法的关键痛点,为大模型 RL 训练提供了更完善的解决方案。