Qwen3——技术报告详解
引言: Qwen3(通义千问第三代)是 Qwen 模型家族的最新版本,包含 6 个 Dense 模型(0.6B 至 32B)和 2 个 MoE 模型(30B-A3B、235B-A22B)。核心创新包括:将「思考模式」与「非思考模式」融合到单一模型中,引入「思考预算」机制动态控制推理深度,以及通过「强到弱蒸馏」高效构建轻量模型。预训练使用 36 万亿 token,覆盖 119 种语言和方言。旗舰模型 Qwen3-235B-A22B 在 AIME’24 达到 85.7、LiveCodeBench v5 达到 70.7、CodeForces 达到 2056,以仅 35% 总参数量超越 DeepSeek-R1 在 17/23 基准上的表现。
阅读指南: 本文较长,建议按需跳转阅读。架构部分介绍 Dense/MoE 模型设计;预训练部分涵盖数据、阶段和基座模型评估;后训练部分是核心亮点,包括思考模式融合、强化学习、蒸馏方法和指令模型评估;结论部分总结未来方向。
✈️ 引言
追求通用人工智能(AGI)乃至超级人工智能(ASI)一直是人类的长期目标。近年来,GPT-4o、Claude 3.7、Gemini 2.5、DeepSeek-V3、Llama-4 以及 Qwen2.5 等大型基础模型展示了朝这一方向的显著进步。这些模型在跨领域、跨任务的数万亿 token 上训练,将人类知识和能力有效蒸馏到模型参数中。此外,通过强化学习优化的推理模型(如 o3、DeepSeek-R1)突显了基础模型在增强推理时间扩展、达到更高智能水平方面的潜力。尽管大多数最先进模型仍为闭源,但开源社区的快速增长已大幅缩小了开源模型与闭源模型之间的性能差距,越来越多的顶级模型正在以开源形式发布,促进了更广泛的人工智能研究与创新。
本报告介绍 Qwen3,即 Qwen 基础模型家族的最新系列。Qwen3 是一系列开源大语言模型(LLM),在多种任务和领域上实现了最先进的性能。作者发布了 Dense 和「混合专家」(MoE)两种架构的模型,参数规模从 0.6B 到 235B,以满足不同下游应用的需求。旗舰模型 Qwen3-235B-A22B 是一个总参数量 235B、每 token 激活 22B 参数的 MoE 模型,确保了高性能与高效推理的兼顾。
Qwen3 引入了几项关键进展以增强功能和可用性。首先,它将两种不同的运行模式——思考模式和非思考模式——整合到单一模型中。这使用户无需在不同模型之间切换(例如从 Qwen2.5 切换到 QwQ),确保开发者和用户能够根据特定任务高效调整模型行为。此外,Qwen3 引入了思考预算(Thinking Budget),为用户提供对模型在任务执行过程中所施加推理努力程度的细粒度控制。这一能力对于优化计算资源和性能至关重要,能够根据实际应用中不同的复杂度需求调整模型的思考行为。再者,Qwen3 在涵盖 119 种语言和方言、共计 36 万亿 token 的数据上进行了预训练,有效增强了其多语言能力,扩大了其在全球化用例和国际应用中的部署潜力。这些进展共同使 Qwen3 成为一个前沿的开源大语言模型家族,能够有效应对跨领域、跨语言的复杂任务。
Qwen3 的预训练过程使用了约 36 万亿 token 的大规模数据集,经过精心策划以确保语言和领域的多样性。为高效扩展训练数据,作者采用了多模态方法:对 Qwen2.5-VL 进行微调以从大量 PDF 文档中提取文本,同时使用 Qwen2.5-Math 和 Qwen2.5-Coder 等领域专用模型生成合成数据。预训练遵循三阶段策略:第一阶段在约 30 万亿 token 上训练以建立坚实的通用知识基础;第二阶段在知识密集型数据上进一步训练以增强 STEM 和编码领域的推理能力;最后第三阶段在长上下文数据上训练,将最大上下文长度从 4,096 扩展到 32,768 token。
为了更好地将基础模型与人类偏好和下游应用对齐,作者采用了多阶段后训练方法,赋予模型思考(推理)和非思考两种模式的能力。前两个阶段专注于通过长链思维(Long-CoT)冷启动微调和面向数学与编码任务的强化学习来发展强大的推理能力。后两个阶段将有推理路径和无推理路径的数据合并到统一数据集中进行进一步微调,使模型能有效处理两种类型的输入,然后应用通用领域的强化学习以提升广泛下游任务的性能。对于较小的模型,使用强到弱蒸馏,利用 off-policy 和 on-policy 的知识迁移来增强其能力。从先进教师模型的蒸馏在性能和训练效率上均显著优于强化学习。
作者对预训练和后训练版本的模型在涵盖多种任务和领域的综合基准集上进行了评估。实验结果表明,预训练基座模型达到了最先进的性能。后训练模型无论在思考模式还是非思考模式下,均与 o1、o3-mini 和 DeepSeek-V3 等领先闭源模型和大型 MoE 模型具有竞争力。值得注意的是,Qwen3 模型在编码、数学和 Agent 相关任务上表现尤为突出。例如,旗舰模型 Qwen3-235B-A22B 在 AIME’24 上达到 85.7,AIME’25 上达到 81.5,LiveCodeBench v5 上达到 70.7,CodeForces 上达到 2056,BFCL v3 上达到 70.8。此外,Qwen3 系列中的其他模型相对于其规模也表现出色。增加思考 token 的思考预算可在各种任务上带来持续的性能提升。
🏗️ 模型架构
Qwen3 系列包含 6 个 Dense 模型——Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B 和 Qwen3-32B,以及 2 个 MoE 模型——Qwen3-30B-A3B 和 Qwen3-235B-A22B。旗舰模型 Qwen3-235B-A22B 总参数量 235B,激活参数量 22B。
Qwen3 Dense 模型的架构与 Qwen2.5 类似,采用「分组查询注意力」(GQA)、SwiGLU 激活函数、「旋转位置编码」(RoPE)以及带预归一化的 RMSNorm。此外,Qwen3 移除了 Qwen2 中使用的 QKV-bias,并在注意力机制中引入 QK-Norm 以确保稳定训练。Dense 模型架构的关键信息如下表所示:
| 模型 | 层数 | 注意力头 (Q / KV) | Tie Embedding | 上下文长度 |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | 是 | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | 是 | 32K |
| Qwen3-4B | 36 | 32 / 8 | 是 | 128K |
| Qwen3-8B | 36 | 32 / 8 | 否 | 128K |
| Qwen3-14B | 40 | 40 / 8 | 否 | 128K |
| Qwen3-32B | 64 | 64 / 8 | 否 | 128K |
Qwen3 MoE 模型与 Dense 模型共享相同的基础架构。作者沿用 Qwen2.5-MoE 的做法,实现了「细粒度专家分割」。Qwen3 MoE 模型共有 128 个专家,每 token 激活 8 个专家。与 Qwen2.5-MoE 不同的是,Qwen3 MoE 设计中排除了共享专家。此外,采用全局批次负载均衡损失以促进专家专业化。这些架构和训练创新在下游任务上带来了显著的性能提升。MoE 模型架构的关键信息如下:
| 模型 | 层数 | 注意力头 (Q / KV) | 专家数 (总 / 激活) | 上下文长度 |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K |
Qwen3 模型使用 Qwen 的分词器,采用字节级字节对编码(BBPE),词表大小为 151,669。
Qwen2.5 → Qwen3 架构要点变化: 移除 QKV-bias,引入 QK-Norm 稳定训练;MoE 模型取消共享专家,改用全局批次负载均衡损失促进专家专业化;专家数统一为 128/8(总数/激活数)。
📊 预训练
预训练数据
相比 Qwen2.5,Qwen3 的训练数据规模和多样性有了大幅扩展。具体而言,预训练 token 数量增加了两倍,覆盖的语言增加了三倍。所有 Qwen3 模型在一个大规模多样化数据集上训练,涵盖 119 种语言和方言,总计 36 万亿 token。该数据集包含编码、STEM(科学、技术、工程和数学)、推理任务、书籍、多语言文本和合成数据等多个领域的高质量内容。
为进一步扩展预训练数据语料,作者首先使用 Qwen2.5-VL 模型对大量 PDF 类文档进行文本识别。识别出的文本随后使用 Qwen2.5 模型进行精炼以提升质量。通过这一两步流程,获得了总计数万亿的额外高质量文本 token。此外,作者使用 Qwen2.5、Qwen2.5-Math 和 Qwen2.5-Coder 模型合成了不同格式的数万亿文本 token,包括教科书、问答、指令和代码片段,覆盖数十个领域。最后,通过引入额外的多语言数据和更多语言进一步扩展预训练语料。与 Qwen2.5 的预训练数据相比,支持的语言数量从 29 种显著增加到 119 种,增强了模型的语言覆盖范围和跨语言能力。
作者还开发了一套多语言数据标注系统,旨在提升训练数据的质量和多样性。该系统已应用于大规模预训练数据集,对超过 30 万亿 token 进行了多维度标注,包括教育价值、领域和安全性等。这些细粒度标注支持更有效的数据过滤和组合。与以往在数据源或领域层面优化数据混合的研究不同,Qwen3 的方法通过在小型代理模型上进行大量消融实验,在实例级别利用细粒度数据标签优化数据混合比例。
预训练阶段
Qwen3 模型通过三阶段流程进行预训练:
通用阶段(S1):在第一阶段,所有 Qwen3 模型在超过 30 万亿 token 上训练,序列长度为 4,096 token。在此阶段,模型在语言能力和通用世界知识上得到充分预训练,训练数据覆盖 119 种语言和方言。
推理阶段(S2):为进一步提升推理能力,作者优化了该阶段的预训练语料,增加了 STEM、编码、推理和合成数据的比例。模型在约 5 万亿更高质量的 token 上继续预训练,序列长度为 4,096 token。同时在此阶段加速了学习率衰减。
长上下文阶段:在最终预训练阶段,作者收集高质量长上下文语料以扩展 Qwen3 模型的上下文长度。所有模型在数千亿 token 上预训练,序列长度为 32,768 token。长上下文语料包含 75% 长度在 16,384 到 32,768 token 之间的文本,以及 25% 长度在 4,096 到 16,384 token 之间的文本。参照 Qwen2.5 的做法,使用 ABF 技术将 RoPE 的基频从 10,000 增加到 1,000,000。同时引入 YARN 和 DCA(Dual Chunk Attention)以在推理时实现序列长度容量的四倍扩展。
与 Qwen2.5 类似,作者基于上述三个预训练阶段开发了用于最优超参数(如学习率调度和 batch size)预测的「缩放定律」。通过大量实验,系统研究了模型架构、训练数据、训练阶段与最优训练超参数之间的关系,最终为每个 Dense 或 MoE 模型设定了预测的最优学习率和 batch size 策略。
预训练评估
作者对 Qwen3 系列基座语言模型进行了全面评估。基座模型的评估主要关注其在通用知识、推理、数学、科学知识、编码和多语言能力方面的性能。预训练基座模型的评估数据集包含 15 个基准:
- 通用任务:MMLU(5-shot)、MMLU-Pro(5-shot, CoT)、MMLU-Redux(5-shot)、BBH(3-shot, CoT)、SuperGPQA(5-shot, CoT)
- 数学与 STEM 任务:GPQA(5-shot, CoT)、GSM8K(4-shot, CoT)、MATH(4-shot, CoT)
- 编码任务:EvalPlus(0-shot,HumanEval、MBPP、HumanEval+、MBPP+ 的平均值)、MultiPL-E(0-shot,Python、C++、Java、PHP、TypeScript、C#、Bash、JavaScript)、MBPP-3shot、CRUX-O(1-shot)
- 多语言任务:MGSM(8-shot, CoT)、MMMLU(5-shot)、INCLUDE(5-shot)
所有基线模型均使用相同的评估流程和广泛使用的评估设置以确保公平比较。
Qwen3-235B-A22B-Base 与此前类似规模的 MoE 模型 Qwen2.5-Plus-Base 以及其他领先开源基座模型进行了对比。结果如下表所示:
| 基准 | Qwen2.5-72B | Qwen2.5-Plus | Llama-4-Maverick | DeepSeek-V3 | Qwen3-235B-A22B |
|---|---|---|---|---|---|
| 架构 | Dense | MoE | MoE | MoE | MoE |
| 总参数量 | 72B | 271B | 402B | 671B | 235B |
| 激活参数量 | 72B | 37B | 17B | 37B | 22B |
| MMLU | 86.06 | 85.02 | 85.16 | 87.19 | 87.81 |
| MMLU-Redux | 83.91 | 82.69 | 84.05 | 86.14 | 87.40 |
| MMLU-Pro | 58.07 | 63.52 | 63.91 | 59.84 | 68.18 |
| SuperGPQA | 36.20 | 37.18 | 40.85 | 41.53 | 44.06 |
| BBH | 86.30 | 85.60 | 83.62 | 86.22 | 88.87 |
| GPQA | 45.88 | 41.92 | 43.94 | 41.92 | 47.47 |
| GSM8K | 91.50 | 91.89 | 87.72 | 87.57 | 94.39 |
| MATH | 62.12 | 62.78 | 63.32 | 62.62 | 71.84 |
| EvalPlus | 65.93 | 61.43 | 68.38 | 63.75 | 77.60 |
| MultiPL-E | 58.70 | 62.16 | 57.28 | 62.26 | 65.94 |
| MBPP | 76.00 | 74.60 | 75.40 | 74.20 | 81.40 |
| CRUX-O | 66.20 | 68.50 | 77.00 | 76.60 | 79.00 |
| MGSM | 82.40 | 82.21 | 79.69 | 82.68 | 83.53 |
| MMMLU | 84.40 | 83.49 | 83.09 | 85.88 | 86.70 |
| INCLUDE | 69.05 | 66.97 | 73.47 | 75.17 | 73.46 |
Qwen3-235B-A22B-Base 在大多数评估基准上取得了最高分。具体分析如下:(1) 与参数量约为其两倍的 Llama-4-Maverick-Base 相比,Qwen3-235B-A22B-Base 在大多数基准上仍表现更优。(2) 与此前最先进的开源模型 DeepSeek-V3-Base 相比,Qwen3-235B-A22B-Base 以仅约 1/3 的总参数量和 2/3 的激活参数量在 15 个评估基准中的 14 个上胜出,展示了模型的强大性能和高性价比。(3) 与此前类似规模的 MoE 模型 Qwen2.5-Plus 相比,Qwen3-235B-A22B-Base 以更少的参数和激活参数量显著超越后者,体现了 Qwen3 在预训练数据、训练策略和模型架构方面的显著优势。(4) 与此前的旗舰开源 Dense 模型 Qwen2.5-72B-Base 相比,Qwen3-235B-A22B-Base 在所有基准上超越后者,且使用不到 1/3 的激活参数量。
Qwen3-32B-Base 与类似规模的基线模型进行了对比,包括 Gemma-3-27B 和 Qwen2.5-32B,以及两个更强的基线:参数量为 Qwen3-32B 三倍但激活参数量为其一半的 Llama-4-Scout,和参数量超过其两倍的 Qwen2.5-72B-Base。
| 基准 | Qwen2.5-32B | Qwen2.5-72B | Gemma-3-27B | Llama-4-Scout | Qwen3-32B |
|---|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | MoE | Dense |
| 总参数量 | 32B | 72B | 27B | 109B | 32B |
| MMLU | 83.32 | 86.06 | 78.69 | 78.27 | 83.61 |
| MMLU-Pro | 55.10 | 58.07 | 52.88 | 56.13 | 65.54 |
| SuperGPQA | 33.55 | 36.20 | 29.87 | 26.51 | 39.78 |
| BBH | 84.48 | 86.30 | 79.95 | 82.40 | 87.38 |
| GPQA | 47.97 | 45.88 | 26.26 | 40.40 | 49.49 |
| MATH | 57.70 | 62.12 | 51.78 | 51.66 | 61.62 |
| EvalPlus | 66.25 | 65.93 | 55.78 | 59.90 | 72.05 |
| MultiPL-E | 58.30 | 58.70 | 45.03 | 47.38 | 67.06 |
| MGSM | 78.12 | 82.40 | 73.74 | 79.93 | 83.06 |
结果支持三个关键结论:(1) 与类似规模模型相比,Qwen3-32B-Base 在大多数基准上优于 Qwen2.5-32B-Base 和 Gemma-3-27B Base。特别是在 MMLU-Pro(65.54)和 SuperGPQA(39.78)上显著超越前代 Qwen2.5-32B-Base,编码基准分数也显著高于所有基线模型。(2) Qwen3-32B-Base 虽然参数量不到 Qwen2.5-72B-Base 的一半,但在 15 个评估基准中的 10 个上表现优于后者,在编码、数学和推理基准上具有显著优势。(3) 与 Llama-4-Scout-Base 相比,Qwen3-32B-Base 仅以其 1/3 的参数量在所有 15 个基准上显著超越后者。
Qwen3-14B-Base 和 Qwen3-30B-A3B-Base 与类似规模的基线进行了对比。值得注意的是,仅用 1/5 的激活非嵌入参数量,Qwen3-30B-A3B 在所有任务上显著优于 Qwen2.5-14B-Base,并达到了与 Qwen3-14B-Base 和 Qwen2.5-32B-Base 可比的性能,这在推理和训练成本方面带来了显著优势。
Qwen3-8B / 4B / 1.7B / 0.6B-Base 端侧模型也保持了强劲性能。所有模型在几乎所有基准上持续保持强劲表现。值得注意的是,Qwen3-8B / 4B / 1.7B-Base 甚至在超过半数的基准上优于更大规模的 Qwen2.5-14B / 7B / 3B Base 模型,尤其在 STEM 相关和编码基准上,反映了 Qwen3 模型的显著进步。
基于上述全面评估,可以总结出 Qwen3 基座模型的几个关键结论:
与此前开源的最先进 Dense 和 MoE 基座模型(如 DeepSeek-V3 Base、Llama-4-Maverick Base 和 Qwen2.5-72B-Base)相比,Qwen3-235B-A22B-Base 以显著更少的总参数量或激活参数量在大多数任务上超越这些模型。
对于 Qwen3 MoE 基座模型:(a) 使用相同预训练数据,Qwen3 MoE 基座模型仅需 1/5 的激活参数量即可达到与 Qwen3 Dense 基座模型相似的性能;(b) 得益于架构改进、训练 token 规模扩大和更先进的训练策略,Qwen3 MoE 基座模型以不到 1/2 的激活参数量和更少的总参数量即可超越 Qwen2.5 MoE 基座模型;(c) 即使仅用 Qwen2.5 Dense 基座模型 1/10 的激活参数量,Qwen3 MoE 基座模型也能达到可比性能,在推理和训练成本方面带来显著优势。
Qwen3 Dense 基座模型的整体性能可与更高参数规模的 Qwen2.5 基座模型媲美。例如,Qwen3-1.7B / 4B / 8B / 14B / 32B-Base 分别达到了与 Qwen2.5-3B / 7B / 14B / 32B / 72B-Base 可比的性能。尤其在 STEM、编码和推理基准上,Qwen3 Dense 基座模型甚至超越了更高参数规模的 Qwen2.5 基座模型。
代际跨越: Qwen3 基座模型实现了显著的「以小博大」——235B-A22B 以 1/3 总参数量在 14/15 基准上超越 DeepSeek-V3;MoE 模型仅需 Dense 模型 1/5 激活参数即达相似性能;每一代 Dense 模型均可媲美上一代两倍规模的模型。
🚀 后训练
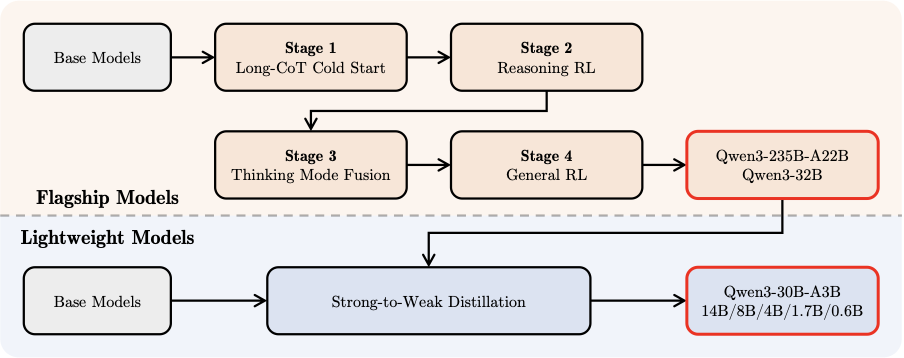
Qwen3 的后训练流程围绕两个核心目标进行战略性设计:
思考控制:将「非思考」和「思考」两种模式整合到统一框架中,为用户提供是否让模型进行推理的灵活性,并通过指定思考过程的 token 预算来控制思考深度。
强到弱蒸馏:旨在简化和优化轻量模型的后训练流程。通过利用大规模模型的知识,大幅降低构建小规模模型所需的计算成本和开发工作量。
如上图所示,Qwen3 系列中的旗舰模型遵循精心设计的四阶段训练流程。前两个阶段专注于发展模型的「思考」能力,后两个阶段旨在将强大的「非思考」功能整合到模型中。
初步实验表明,直接将教师模型的输出 logits 蒸馏到轻量学生模型中,可以有效增强其性能,同时保持对推理过程的细粒度控制。这种方法无需为每个小规模模型单独执行完整的四阶段训练流程,带来了更好的即时性能(更高的 Pass@1 分数),也提升了模型的探索能力(更好的 Pass@64 结果),且仅需四阶段训练方法 1/10 的 GPU 时间,训练效率大幅提升。
Long-CoT 冷启动
作者首先策划了一个涵盖广泛类别的综合数据集,包括数学、代码、逻辑推理和通用 STEM 问题。数据集中的每个问题都配有经过验证的参考答案或基于代码的测试用例。该数据集作为长链思维(Long-CoT)训练「冷启动」阶段的基础。
数据集构建涉及严格的两阶段过滤流程:查询过滤和响应过滤。在查询过滤阶段,使用 Qwen2.5-72B-Instruct 识别并移除不易验证的查询,包括包含多个子问题的查询或要求一般文本生成的查询。此外,排除 Qwen2.5-72B-Instruct 无需使用 CoT 推理即可正确回答的查询,以防止模型依赖表面猜测,确保只保留需要更深层推理的复杂问题。同时使用 Qwen2.5-72B-Instruct 对每个查询的领域进行标注,以维持数据集中的领域平衡表示。
在预留验证查询集后,使用 QwQ-32B 为每个剩余查询生成
随后,选取精炼数据集的一个子集用于推理模式的初始冷启动训练。此阶段的目标是在模型中注入基础推理模式,而不过度强调即时推理性能。这种方法确保模型的潜力不受限制,在后续强化学习(RL)阶段允许更大的灵活性和改进空间。为有效实现这一目标,有意在此准备阶段最小化训练样本数量和训练步数。
推理强化学习
推理 RL 阶段使用的查询-验证器对必须满足以下四项标准:(1) 未在冷启动阶段使用;(2) 对冷启动模型而言是可学习的;(3) 尽可能具有挑战性;(4) 覆盖广泛的子领域。最终收集了总计 3,995 个查询-验证器对,并采用 GRPO 更新模型参数。
作者观察到,使用大 batch size 和高 rollout 数量,结合 off-policy 训练以提高样本效率,对训练过程是有益的。作者还解决了如何通过控制模型熵稳定上升或保持稳定来平衡探索与利用的问题,这对维持稳定训练至关重要。最终,在单次 RL 运行过程中实现了训练奖励和验证性能的持续改进,无需对超参数进行任何手动干预。例如,Qwen3-235B-A22B 模型的 AIME’24 分数在总共 170 个 RL 训练步骤中从 70.1 提升到 85.1。
思考模式融合
思考模式融合阶段的目标是将「非思考」能力整合到此前开发的「思考」模型中。这种方法允许开发者管理和控制推理行为,同时降低为思考和非思考任务部署不同模型的成本和复杂性。为此,在 Reasoning RL 模型上进行持续监督微调(SFT),并设计聊天模板以融合两种模式。此外,作者发现能够熟练处理两种模式的模型在不同思考预算下也能表现一致良好。
SFT 数据构建。SFT 数据集结合了「思考」和「非思考」两类数据。为确保 Stage 2 模型的性能不被额外 SFT 所削弱,「思考」数据通过使用 Stage 2 模型本身对 Stage 1 查询进行拒绝采样生成。「非思考」数据则经过精心策划,覆盖编码、数学、指令遵循、多语言任务、创意写作、问答和角色扮演等多样化任务。此外,采用自动生成的检查清单评估「非思考」数据的响应质量。为增强低资源语言任务的性能,特别增加了翻译任务的比例。
聊天模板设计。为更好地整合两种模式并使用户能动态切换模型的思考过程,作者为 Qwen3 设计了聊天模板。具体而言,对于思考模式和非思考模式的样本,分别在用户查询或系统消息中引入 /think 和 /no_think 标志,使模型根据用户输入选择适当的思考模式。对于非思考模式样本,在助手响应中保留一个空的思考块。这一设计确保了模型内部的格式一致性,并允许开发者通过在聊天模板中拼接空思考块来阻止模型进行思考行为。默认情况下,模型在思考模式下运行。对于更复杂的多轮对话,随机在用户查询中插入多个 /think 和 /no_think 标志,模型响应遵循最后遇到的标志。
思考预算。思考模式融合的一个额外优势是,一旦模型学会在非思考和思考两种模式下响应,它自然发展出处理中间情况的能力——基于不完整的思考生成响应。这为实现模型思考过程的预算控制奠定了基础。具体而言,当模型思考的长度达到用户定义的阈值时,手动终止思考过程并插入停止思考指令。在该指令插入后,模型基于其到该点累积的推理生成最终响应。值得注意的是,这种能力并非显式训练而来,而是作为思考模式融合的自然结果涌现的。
涌现能力: 思考预算控制并非通过专门训练获得,而是模型在学会思考/非思考模式切换后自然涌现的能力。这意味着模型内部发展出了对「推理深度」的隐式理解,能够在被截断时仍基于已有推理给出合理回答。
通用强化学习
通用 RL 阶段旨在广泛增强模型在多样化场景下的能力和稳定性。为此,作者建立了一套涵盖超过 20 种不同任务的精密奖励系统,每种任务都有定制的评分标准。这些任务特别针对以下核心能力的增强:
指令遵循:确保模型准确解释和遵循用户指令,包括与内容、格式、长度和结构化输出使用相关的要求,提供符合用户期望的响应。
格式遵循:除显式指令外,模型需遵守特定的格式惯例。例如,正确响应
/think和/no_think标志以在思考和非思考模式之间切换,并在最终输出中一致使用指定 token(如<think>和</think>)来分隔思考和响应部分。偏好对齐:对于开放式查询,偏好对齐专注于提升模型的帮助性、参与度和风格,最终提供更自然和令人满意的用户体验。
Agent 能力:训练模型通过指定接口正确调用工具。在 RL rollout 过程中,允许模型与真实环境执行反馈进行完整的多轮交互循环,从而提升其在长时间跨度决策任务中的性能和稳定性。
专域场景能力:在更专业的场景中,设计针对特定上下文的任务。例如,在「检索增强生成」(RAG)任务中,引入奖励信号引导模型生成准确且上下文适当的响应,从而最小化幻觉风险。
为上述任务提供反馈,使用了三种不同类型的奖励:
规则奖励:规则奖励已广泛用于推理 RL 阶段,对指令遵循和格式遵守等通用任务也很有用。精心设计的规则奖励能以高精度评估模型输出的正确性,防止 reward hacking 等问题。
带参考答案的模型奖励:为每个查询提供参考答案,并提示 Qwen2.5-72B-Instruct 根据该参考答案对模型响应进行评分。这种方法允许更灵活地处理多样化任务而无需严格格式化,避免纯规则奖励可能产生的假阴性。
无参考答案的模型奖励:利用人类偏好数据训练奖励模型,为模型响应分配标量分数。这种不依赖参考答案的方法能处理更广泛的查询,同时有效增强模型的参与度和帮助性。
强到弱蒸馏
强到弱蒸馏流程专门设计用于优化轻量模型,涵盖 5 个 Dense 模型(Qwen3-0.6B、1.7B、4B、8B 和 14B)和 1 个 MoE 模型(Qwen3-30B-A3B)。这种方法在增强模型性能的同时,有效赋予其稳健的模式切换能力。蒸馏过程分为两个主要阶段:
Off-policy 蒸馏:在初始阶段,结合教师模型在
/think和/no_think两种模式下生成的输出进行响应蒸馏。这帮助轻量学生模型发展基础推理技能和在不同思考模式之间切换的能力,为下一个 on-policy 训练阶段奠定坚实基础。On-policy 蒸馏:在此阶段,学生模型生成 on-policy 序列用于微调。具体而言,采样提示,学生模型在
/think或/no_think模式下生成响应。然后通过对齐其 logits 与教师模型(Qwen3-32B 或 Qwen3-235B-A22B)来最小化 KL 散度,对学生模型进行微调。
后训练评估
为全面评估指令微调模型的质量,作者采用自动基准在思考和非思考两种模式下评估模型性能。这些基准分为以下几个维度:
- 通用任务:MMLU-Redux、GPQA-Diamond、C-Eval、LiveBench (2024-11-25)。其中 GPQA-Diamond 对每个查询采样 10 次并报告平均准确率。
- 对齐任务:IFEval(strict-prompt 准确率)、Arena-Hard、AlignBench v1.1、Creative Writing V3、WritingBench。
- 数学与文本推理:MATH-500、AIME’24 和 AIME’25、ZebraLogic、AutoLogi。其中 AIME 每年的题目包含 Part I 和 Part II 共 30 道题,每道题采样 64 次取平均准确率作为最终分数。
- Agent 与编码:BFCL v3、LiveCodeBench (v5, 2024.10-2025.02)、CodeForces(CodeElo 的 Elo 评分)。
- 多语言任务:Multi-IF(8 种语言)、INCLUDE(44 种语言)、MMMLU(14 种语言)、MT-AIME2024(55 种语言)、PolyMath(18 种语言)、MLogiQA(10 种语言)。
对于思考模式,采样温度 0.6,top-p 0.95,top-k 20;对于非思考模式,温度 0.7,top-p 0.8,top-k 20,presence penalty 1.5。两种模式下最大输出长度设为 32,768 token,AIME’24 和 AIME’25 除外,其输出长度扩展到 38,912 token 以提供充足的思考空间。
Qwen3-235B-A22B(思考模式) 与 OpenAI-o1、DeepSeek-R1、Grok-3-Beta (Think) 和 Gemini2.5-Pro 等推理基线进行了对比:
| 基准 | OpenAI-o1 | DeepSeek-R1 | Grok-3 (Think) | Gemini2.5-Pro | Qwen3-235B-A22B |
|---|---|---|---|---|---|
| MMLU-Redux | 92.8 | 92.9 | - | 93.7 | 92.7 |
| GPQA-Diamond | 78.0 | 71.5 | 80.2 | 84.0 | 71.1 |
| C-Eval | 85.5 | 91.8 | - | 82.9 | 89.6 |
| LiveBench | 75.7 | 71.6 | - | 82.4 | 77.1 |
| IFEval | 92.6 | 83.3 | - | 89.5 | 83.4 |
| Arena-Hard | 92.1 | 92.3 | - | 96.4 | 95.6 |
| AlignBench v1.1 | 8.86 | 8.76 | - | 9.03 | 8.94 |
| Creative Writing v3 | 81.7 | 85.5 | - | 86.0 | 84.6 |
| WritingBench | 7.69 | 7.71 | - | 8.09 | 8.03 |
| MATH-500 | 96.4 | 97.3 | - | 98.8 | 98.0 |
| AIME’24 | 74.3 | 79.8 | 83.9 | 92.0 | 85.7 |
| AIME’25 | 79.2 | 70.0 | 77.3 | 86.7 | 81.5 |
| ZebraLogic | 81.0 | 78.7 | - | 87.4 | 80.3 |
| AutoLogi | 79.8 | 86.1 | - | 85.4 | 89.0 |
| BFCL v3 | 67.8 | 56.9 | - | 62.9 | 70.8 |
| LiveCodeBench v5 | 63.9 | 64.3 | 70.6 | 70.4 | 70.7 |
| CodeForces | 1891 | 2029 | - | 2001 | 2056 |
| Multi-IF | 48.8 | 67.7 | - | 77.8 | 71.9 |
| INCLUDE | 84.6 | 82.7 | - | 85.1 | 78.7 |
| MMMLU | 88.4 | 86.4 | - | 86.9 | 84.3 |
| MT-AIME2024 | 67.4 | 73.5 | - | 76.9 | 80.8 |
| PolyMath | 38.9 | 47.1 | - | 52.2 | 54.7 |
| MLogiQA | 75.5 | 73.8 | - | 75.6 | 77.1 |
以仅 60% 的激活参数和 35% 的总参数,Qwen3-235B-A22B(思考模式)在 17/23 基准上超越 DeepSeek-R1,特别在推理需求高的任务(如数学、Agent 和编码)上表现出色,展示了开源模型中最先进的推理能力。同时,Qwen3-235B-A22B(思考模式)与闭源的 OpenAI-o1、Grok-3-Beta (Think) 和 Gemini2.5-Pro 高度竞争,大幅缩小了开源模型与闭源模型在推理能力上的差距。
Qwen3-235B-A22B(非思考模式) 与 GPT-4o-2024-11-20、DeepSeek-V3、Qwen2.5-72B-Instruct 和 LLaMA-4-Maverick 等非推理基线进行了对比:
| 基准 | GPT-4o | DeepSeek-V3 | Qwen2.5-72B-Inst | LLaMA-4-Maverick | Qwen3-235B-A22B |
|---|---|---|---|---|---|
| MMLU-Redux | 87.0 | 89.1 | 86.8 | 91.8 | 89.2 |
| GPQA-Diamond | 46.0 | 59.1 | 49.0 | 69.8 | 62.9 |
| C-Eval | 75.5 | 86.5 | 84.7 | 83.5 | 86.1 |
| LiveBench | 52.2 | 60.5 | 51.4 | 59.5 | 62.5 |
| IFEval | 86.5 | 86.1 | 84.1 | 86.7 | 83.2 |
| Arena-Hard | 85.3 | 85.5 | 81.2 | 82.7 | 96.1 |
| AlignBench v1.1 | 8.42 | 8.64 | 7.89 | 7.97 | 8.91 |
| Creative Writing v3 | 81.1 | 74.0 | 61.8 | 61.3 | 80.4 |
| WritingBench | 7.11 | 6.49 | 7.06 | 5.46 | 7.70 |
| MATH-500 | 77.2 | 90.2 | 83.6 | 90.6 | 91.2 |
| AIME’24 | 11.1 | 39.2 | 18.9 | 38.5 | 40.1 |
| AIME’25 | 7.6 | 28.8 | 15.0 | 15.9 | 24.7 |
| ZebraLogic | 27.4 | 42.1 | 26.6 | 40.0 | 37.7 |
| AutoLogi | 65.9 | 76.1 | 66.1 | 75.2 | 83.3 |
| BFCL v3 | 72.5 | 57.6 | 63.4 | 52.9 | 68.0 |
| LiveCodeBench v5 | 32.7 | 33.1 | 30.7 | 37.2 | 35.3 |
| CodeForces | 864 | 1134 | 859 | 712 | 1387 |
| Multi-IF | 65.6 | 55.6 | 65.3 | 75.5 | 70.2 |
| MT-AIME2024 | 9.2 | 20.9 | 12.7 | 27.0 | 32.4 |
| PolyMath | 13.7 | 20.4 | 16.9 | 26.1 | 27.0 |
| MLogiQA | 57.4 | 58.9 | 59.3 | 59.9 | 67.6 |
Qwen3-235B-A22B(非思考模式)超越了其他领先开源模型(DeepSeek-V3、LLaMA-4-Maverick 和 Qwen2.5-72B-Instruct),并在 18/23 基准上超越闭源 GPT-4o-2024-11-20,表明即使未经深度思考过程增强,其固有能力也极为强大。
Qwen3-32B(思考模式) 与 DeepSeek-R1-Distill-Llama-70B、OpenAI-o3-mini (medium) 和 QwQ-32B 进行了对比:
| 基准 | R1-Distill-Llama-70B | QwQ-32B | o3-mini (medium) | Qwen3-32B |
|---|---|---|---|---|
| MMLU-Redux | 89.3 | 90.0 | 90.0 | 90.9 |
| GPQA-Diamond | 65.2 | 65.6 | 76.8 | 68.4 |
| LiveBench | 54.5 | 72.0 | 70.0 | 74.9 |
| Arena-Hard | 60.6 | 89.5 | 89.0 | 93.8 |
| AIME’24 | 70.0 | 79.5 | 79.6 | 81.4 |
| AIME’25 | 56.3 | 69.5 | 74.8 | 72.9 |
| ZebraLogic | 71.3 | 76.8 | 88.9 | 88.8 |
| BFCL v3 | 49.3 | 66.4 | 64.6 | 70.3 |
| LiveCodeBench v5 | 54.5 | 62.7 | 66.3 | 65.7 |
| CodeForces | 1633 | 1982 | 2036 | 1977 |
| Multi-IF | 57.6 | 68.3 | 48.4 | 73.0 |
| MT-AIME2024 | 29.3 | 68.0 | 73.9 | 75.0 |
Qwen3-32B(思考模式)在 17/23 基准上超越 QwQ-32B,成为 32B 参数规模下新的最先进推理模型。同时与闭源 OpenAI-o3-mini (medium) 竞争,在对齐和多语言性能上更具优势。
Qwen3-32B(非思考模式) 展现出优于所有基线的性能。特别是,与拥有两倍多参数的 Qwen2.5-72B-Instruct 相比,Qwen3-32B 在通用任务上性能持平,在对齐、多语言和推理相关任务上具有显著优势,再次证明了 Qwen3 相对于 Qwen2.5 系列的根本性进步。
Qwen3-30B-A3B 和 Qwen3-14B 在思考模式下均与 QwQ-32B 高度竞争,尤其在推理相关基准上。值得注意的是,Qwen3-30B-A3B 以更小的模型规模和不到 1/10 的激活参数达到了与 QwQ-32B 可比的性能,展示了强到弱蒸馏方法在赋予轻量模型深层推理能力方面的有效性。在非思考模式下,两者在大多数基准上超越非推理基线,以显著更少的激活和总参数量超越此前的 Qwen2.5-32B-Instruct 模型。
Qwen3-8B / 4B / 1.7B / 0.6B 等端侧模型也展现出令人印象深刻的性能。这些模型在思考或非思考模式下均超越了参数量更多的基线模型(包括此前的 Qwen2.5 模型),再次证明了强到弱蒸馏方法的有效性,使以大幅降低的成本和工作量构建轻量 Qwen3 模型成为可能。
根据评估结果,可总结出以下关键结论:(1) 旗舰模型 Qwen3-235B-A22B 在思考和非思考两种模式下均展示了开源模型中最先进的整体性能,超越 DeepSeek-R1 和 DeepSeek-V3 等强基线,并与 OpenAI-o1、Gemini2.5-Pro 和 GPT-4o 等闭源领先模型高度竞争。(2) 旗舰 Dense 模型 Qwen3-32B 在大多数基准上超越此前最强推理模型 QwQ-32B,并与闭源 OpenAI-o3-mini 表现相当。在非思考模式下也表现出色,超越此前旗舰 Qwen2.5-72B-Instruct。(3) 轻量模型在参数量相近或更大的开源模型中持续保持优越性能,证明了强到弱蒸馏方法的成功。
讨论
思考预算的有效性。为验证 Qwen3 能否通过增加思考预算提升智能水平,作者在数学、编码和 STEM 领域的四个基准上调整了分配的思考预算。
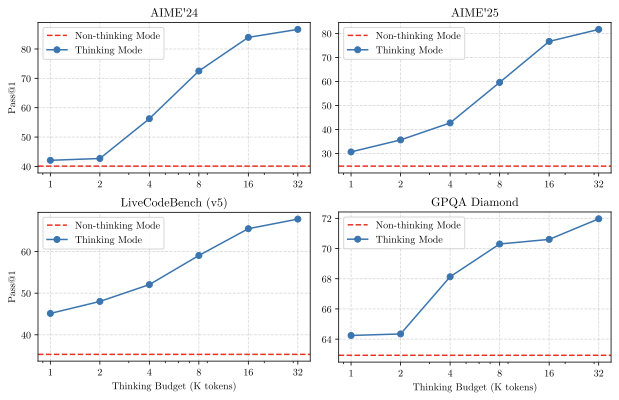
如上图所示,Qwen3 展示了与分配思考预算相关的可扩展且平滑的性能提升。此外,作者观察到,如果进一步将输出长度扩展到 32K 以上,模型性能预计将在未来进一步提升。
On-Policy 蒸馏的有效性和效率。作者通过比较从相同 off-policy 蒸馏 8B 检查点出发的蒸馏与直接强化学习的性能和计算成本(以 GPU 时间衡量),评估了 on-policy 蒸馏的有效性和效率。为简化起见,此比较仅关注数学和代码相关查询。
| 方法 | AIME’24 | AIME’25 | MATH500 | LCB v5 | MMLU-Redux | GPQA | GPU 时间 |
|---|---|---|---|---|---|---|---|
| Off-policy 蒸馏 | 55.0 (90.0) | 42.8 (83.3) | 92.4 | 42.0 | 86.4 | 55.6 | - |
| + 强化学习 | 67.6 (90.0) | 55.5 (83.3) | 94.8 | 52.9 | 86.9 | 61.3 | 17,920h |
| + On-policy 蒸馏 | 74.4 (93.3) | 65.5 (86.7) | 97.0 | 60.3 | 88.3 | 63.3 | 1,800h |
结果表明,蒸馏以仅约 1/10 的 GPU 时间实现了显著更优的性能。此外,教师 logits 蒸馏使学生模型能够扩展其探索空间和增强推理潜力,表现为蒸馏后在 AIME’24 和 AIME’25 基准上 Pass@64 分数的提升(括号中数值)。相比之下,强化学习未带来任何 Pass@64 分数的改善。这些观察突显了利用更强教师模型指导学生模型学习的优势。
蒸馏 vs 强化学习: On-policy 蒸馏仅用 1/10 的 GPU 时间(1,800h vs 17,920h)即实现全面超越 RL 的性能,同时还提升了 Pass@64(探索潜力),而 RL 未能改善 Pass@64。这表明教师指导比自主探索更高效。
思考模式融合和通用 RL 的效果。为评估后训练中思考模式融合和通用强化学习的有效性,作者对 Qwen3-32B 模型各阶段进行了评估。除前述数据集外,还引入了若干内部基准以监控其他能力,包括 CounterFactQA(反事实问题)、LengthCtrl(长度控制创意写作)、ThinkFollow(多轮对话模式切换)和 ToolUse(工具调用稳定性)。
| 基准 | Stage 2 (思考) | Stage 3 (思考) | Stage 3 (非思考) | Stage 4 (思考) | Stage 4 (非思考) |
|---|---|---|---|---|---|
| LiveBench | 68.6 | 70.9 | 57.1 | 74.9 | 59.8 |
| Arena-Hard | 86.8 | 89.4 | 88.5 | 93.8 | 92.8 |
| CounterFactQA* | 50.4 | 61.3 | 64.3 | 68.1 | 66.4 |
| IFEval | 73.0 | 78.4 | 78.4 | 85.0 | 83.2 |
| Multi-IF | 61.4 | 64.6 | 65.2 | 73.0 | 70.7 |
| ThinkFollow* | - | 88.7 | - | 98.9 | - |
| BFCL v3 | 69.0 | 68.4 | 61.5 | 70.3 | 63.0 |
| ToolUse* | 63.3 | 70.4 | 73.2 | 85.5 | 86.5 |
| MMLU-Redux | 91.4 | 91.0 | 86.7 | 90.9 | 85.7 |
| AIME’24 | 83.8 | 81.9 | 28.5 | 81.4 | 31.0 |
| LiveCodeBench v5 | 68.4 | 67.2 | 31.1 | 65.7 | 31.3 |
从结果中可以得出以下结论:
(1) Stage 3 将非思考模式整合到已具备思考能力的模型中。ThinkFollow 基准得分 88.7 表明模型已发展出初步的模式切换能力,但仍偶有错误。Stage 3 还增强了思考模式下的通用和指令遵循能力,CounterFactQA 提升 10.9 分,LengthCtrl 提升 8.0 分。
(2) Stage 4 进一步增强了两种模式下的通用、指令遵循和 Agent 能力。特别是 ThinkFollow 分数提升到 98.9,确保了准确的模式切换。ToolUse 提升幅度显著(思考模式 +15.1,非思考模式 +13.3)。
(3) 对于知识、STEM、数学和编码任务,思考模式融合和通用 RL 未带来显著提升。相反,对于 AIME’24 和 LiveCodeBench 等挑战性任务,思考模式下的性能在这两个训练阶段后实际上有所下降。作者推测这种退化是由于模型在更广泛的通用任务上训练,可能削弱了其处理复杂专业问题的能力。在 Qwen3 开发中,选择接受这一性能权衡以增强模型的整体通用性。
通用性 vs 专业性权衡: Stage 3-4 显著提升了指令遵循、Agent 和模式切换能力,但 AIME’24(83.8→81.4)和 LiveCodeBench(68.4→65.7)等专业推理任务出现小幅退化。Qwen3 团队有意接受这一取舍,优先保障模型的整体通用性。
💡 结论
本技术报告介绍了 Qwen3,即 Qwen 系列的最新版本。Qwen3 同时具备思考模式和非思考模式,允许用户动态管理复杂思考任务所用的 token 数量。模型在涵盖 36 万亿 token 的大规模数据集上进行预训练,能够理解和生成 119 种语言和方言的文本。通过一系列全面评估,Qwen3 在预训练和后训练模型的多种标准基准上展现出强劲性能,涵盖代码生成、数学、推理和 Agent 等相关任务。
在近期未来,研究将聚焦于几个关键方向。首先,将继续扩大预训练规模,使用质量更高、内容更多样的数据。同时,将致力于改进模型架构和训练方法,以实现有效压缩、超长上下文扩展等目标。此外,计划增加强化学习的计算资源投入,特别关注从环境反馈中学习的基于 Agent 的 RL 系统。这将使构建能够解决复杂任务、需要推理时间扩展的 Agent 成为可能。