GRPO——组相对策略优化算法
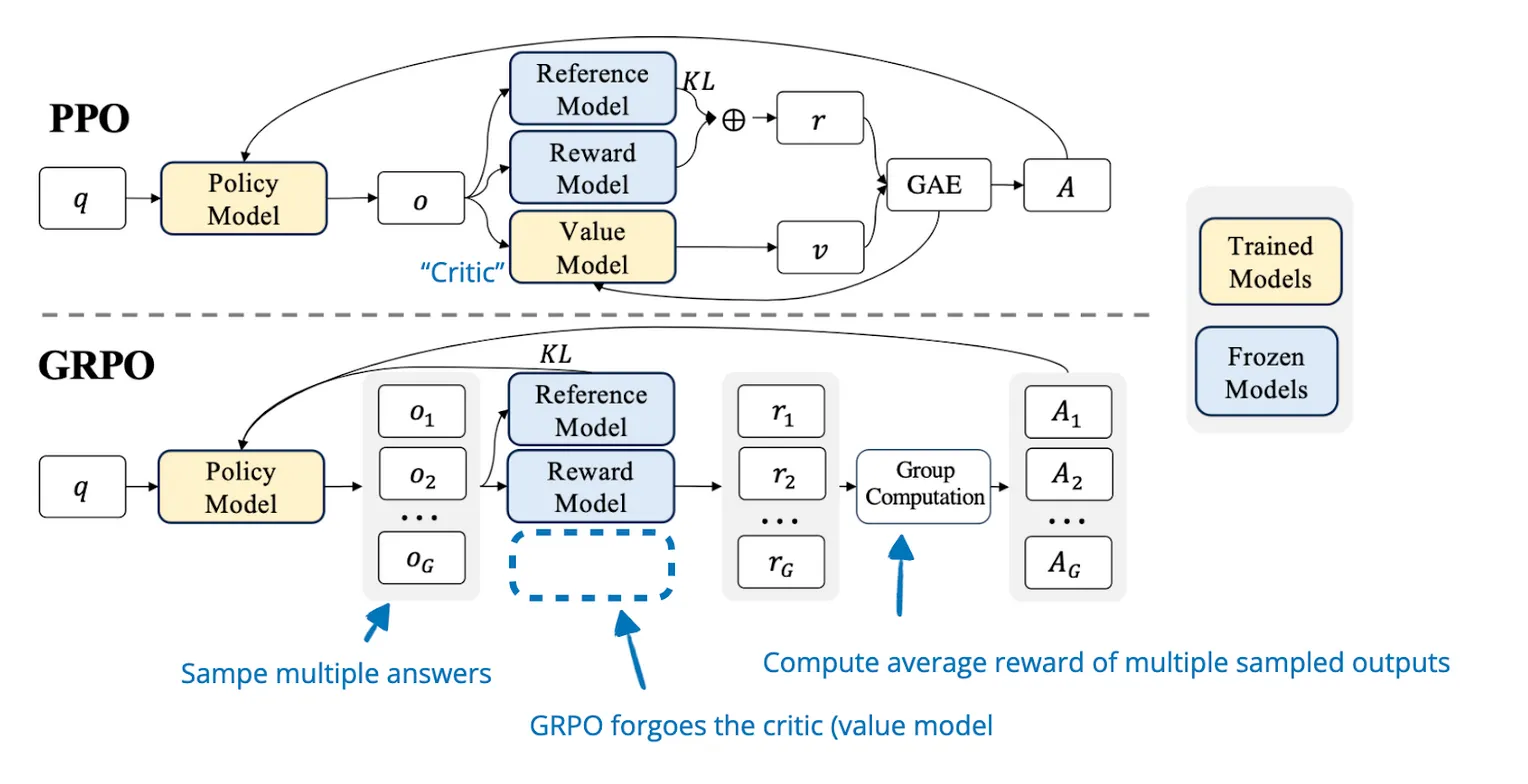
引言: 群体相对策略优化(GRPO)是由 DeepSeek 团队提出的一种专为大语言模型设计的高效强化学习算法。传统的 PPO 算法虽然强大,但需要维护一个与策略模型同等规模的价值网络(Critic),这对显存带来了巨大的压力。GRPO 创造性地摒弃了 Critic 网络,转而利用群体采样的统计特征来估计优势函数。这种方法不仅大幅降低了训练时的显存占用和计算成本,还在数学推理和代码生成等任务上表现出了卓越的性能,是 DeepSeek-R1 等前沿模型背后的核心训练技术。
✈️ GRPO算法介绍
算法归类
GRPO 在强化学习的版图中属于一种轻量级的在线策略优化算法:
- 基于策略 (Policy-Based):直接优化 Actor 网络的参数。
- 在线策略 (On-Policy):通常在 Online RL 阶段使用,模型边生成数据边学习(这一点与 DPO 的离线性质不同)。
- 无Critic模型 (Critic-Less):这是 GRPO 最显著的标签。它移除了 PPO 中的 Critic 网络(价值模型),仅保留 Actor 模型。
- 基于群体 (Group-Based):利用同一个问题生成的多个样本(Group)之间的相对好坏来计算梯度。
适用范围与局限
- 适用范围:
- 超大模型训练:非常适合 70B 甚至 600B 参数量的巨型模型,因为它节省了接近 50% 的显存(不需要加载 Critic)。
- 推理任务 (Reasoning):特别适用于有明确答案或评分标准的任务(如数学题、代码生成),模型可以通过多次尝试自我纠错。
- 局限性:
- 采样开销:对于每一个 Prompt,GRPO 需要生成一组(例如 G = 64)输出。如果推理速度慢,采样过程会成为时间瓶颈。
- 依赖评分器:需要一个可靠的 Reward 函数(规则判断或外部模型)来给这一组输出打分。
基本思想
GRPO的核心思想是通过组内相对奖励来优化策略模型,而不是依赖传统的批评模型(critic model)。
- PPO 的逻辑:Actor 做了一个动作,Critic(老师)给出一个绝对分数的估计 V(s),通过对比实际得分和估计得分来计算优势 A。
- GRPO 的逻辑:Actor 对同一个问题生成 G 个不同的回答。不需要 Critic 来预测分数,而是直接算出这 G 个回答的平均分。
- 考得比平均分高的,优势 A 为正(鼓励)。
- 考得比平均分低的,优势 A 为负(抑制)。
- Baseline 不再是神经网络预测的,而是群体内的平均水平。
🚀 GRPO算法流程
GRPO会在每个状态下采样一组动作,然后根据这些动作的相对表现来调整策略,而不是依赖一个单独的价值网络来估计每个动作的价值。
组内奖励建模
在 GRPO 中,奖励的计算不再依赖训练中的 Critic,而是直接基于环境或规则反馈。 假设对于一个输入问题 q,策略模型 πθ 采样了一组输出 {o1, o2, ..., oG}。
我们对每一个输出 oi 计算奖励 ri。这个奖励可以是:
- 硬规则:数学题做对了得 1 分,做错了得 0 分。
- 软规则:代码通过了所有测试用例得 1 分,通过一半得 0.5 分,格式错误得 -1 分。
- 外部模型:使用一个冻结的 Reward Model 打分。
优化目标
GRPO 的核心在于如何计算优势函数 (Advantage)。 它使用组内标准化的方式来计算优势 Ai:
$$ A_i = \frac{r_i - \text{Mean}(\{r_1, ..., r_G\})}{\text{Std}(\{r_1, ..., r_G\}) + \epsilon} $$
- Mean:组内奖励的平均值(充当了 Baseline)。
- Std:组内奖励的标准差(用于归一化,稳定数值)。
最终的优化目标函数与 PPO 类似,包含 Clip 机制和 KL 散度惩罚:
$$ J_{GRPO}(\theta) = \mathbb{E} \left[ \frac{1}{G} \sum_{i=1}^G \left( \min \left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} A_i, \text{clip}(\dots) A_i \right) - \beta D_{KL}(\pi_\theta || \pi_{ref}) \right) \right] $$
GRPO算法实现流程
与 PPO 复杂的 GAE 计算不同,GRPO 的实现流程更加直观和并行化:
- 输入采样 (Prompt Sampling)
- 从数据集采样一批问题(Prompts),例如 B 个问题。
- 群体生成 (Group Generation)
- 对于每一个问题 q,让旧策略模型 πold 采样生成 G 个不同的回答 {o1, ..., oG}。
- 总共生成 B × G 条数据。
- 奖励评估 (Reward Evaluation)
- 使用奖励函数/规则对这 B × G 个回答进行打分,得到奖励值 {r1, ..., rG}。
- 优势计算 (Advantage Calculation)
- 关键步骤:在每个组内部,计算奖励的均值和方差。
- 使用公式 Ai = (ri − Mean)/Std 得到每个样本的相对优势。
- 策略更新 (Policy Update)
- 将计算出的优势 Ai 代入 PPO-Clip 的损失函数中。
- 也就是:优势大的样本,提高其生成概率;优势小的样本,降低其生成概率。
- 计算 KL 散度(通常通过 πθ 和 πref 的 log 概率差近似)作为正则项。
- 反向传播更新策略模型 πθ 的参数。
🎯 GRPO与PPO
GRPO与PPO区别
GRPO 可以被看作是 PPO 的一个特化且高效的变体。
| 维度 | PPO (Proximal Policy Optimization) | GRPO (Group Relative Policy Optimization) |
|---|---|---|
| 模型数量 | 4 个 (Actor, Critic, Reward, Ref) 显存占用巨大。 | 2 个 (Actor, Ref) 显存占用极低,去掉了 Critic。 |
| 优势估计 | GAE (依赖 Critic) 依赖 Critic 网络的预测值 V(s) 作为基线。 | Group Normalization (无 Critic) 依赖同一组采样的平均分作为基线。 |
| 计算瓶颈 | 梯度更新时的显存和计算量。 | 采样生成阶段的耗时(需要生成 G 次)。 |
| 适用场景 | 通用 RL(游戏、机器人、对话)。 | 大语言模型推理(Math, Code),特别是 DeepSeek-R1 这类场景。 |
GRPO与DPO联系
虽然 GRPO 和 DPO 都去掉了 Critic,但它们处于 RL 的不同阶段。
- 共同点:
- 去中心化:都试图移除 Value/Critic 网络,减轻显存负担。
- 相对性:DPO 比较 Pair (Winner vs Loser),GRPO 比较 Group (Relative to Mean)。
- 不同点:
- 数据来源:
- DPO (Offline):使用预先收集好的静态偏好数据集。模型“看”数据学习。
- GRPO (Online):模型必须自己实时生成数据(Self-Generation),自己探索出高分答案。
- 优化机制:
- DPO:是基于分类概率的损失(Implicit Reward)。
- GRPO:依然是基于强化学习的梯度更新(Explicit Reward + PPO Clip)。
- 数据来源:
总结:如果说 PPO 是全副武装的重装步兵,DPO 是灵活的刺客(离线微调),那么 GRPO 就是为了大兵团作战(超大模型)而生的特种部队——砍掉一切不必要的辎重(Critic),只为了在推理能力的战场上快速进化。