VideoDeepResearch——基于 Agent 工具调用的长视频理解框架
引言: 该研究提出 VideoDeepResearch,一个基于纯文本大推理模型(LRM)与模块化多模态工具包的 Agent 框架,解决了「长视频上下文窗口限制」「RAG 方法泛化能力弱」「计算资源消耗大」等核心问题。该方法在 MLVU、VideoMME-L、LVBench 等基准上取得 SOTA,平均分 66.7 超越 GPT-4o (60.6)。
✈️ VideoDeepResearch 算法介绍
长视频理解(Long Video Understanding, LVU)因视频序列的时序扩展性和复杂语义依赖而极具挑战性。现有主流方法主要依赖大规模多模态大语言模型(MLLM)的扩展上下文窗口,通过将长视频编码为密集 token 序列进行端到端理解。然而,这种「暴力扩展」策略面临着根本性局限:模型需要处理大量冗余信息,计算成本随视频长度线性增长,且性能在长视频上显著下降。
基于检索的生成(RAG)方法试图通过检索相关视频片段来缓解上下文压力,但现有 RAG 方案往往局限于特定任务类别,难以泛化到需要复杂多步推理的任务。例如,单纯的片段检索无法有效处理「动作顺序」「因果关系」「事件计数」等需要全局时序推理的问题。其根本原因在于:检索与理解是解耦的,缺乏智能的查询分解和工具编排能力。
为此,作者提出了 VideoDeepResearch 框架,核心思想是「用组合而非扩展」。该框架采用纯文本大推理模型(LRM)作为智能体(Agent),通过调用五个模块化多模态工具包完成任务,而非依赖单一端到端模型。LRM 负责高层逻辑推理和工具编排决策,多工具包负责具体的感知和检索操作。这种设计将「理解什么」与「如何理解」解耦,使模型能够根据问题特性动态选择最优信息获取路径。
🚀 VideoDeepResearch 算法流程
VideoDeepResearch 框架由两个核心组件构成:纯文本大推理模型(LRM)和五类多模态工具。LRM 采用 DeepSeek-r1-0528,负责分析查询、规划工具调用策略、整合多源信息并生成最终答案。工具包包含检索器、感知器、提取器和浏览器,每个工具专注于特定类型的视频理解任务。工作流程采用经典的「思维-行动」循环:模型生成思考或动作,若为动作则调用相应工具,将结果累积到上下文中,直至模型决定直接回答。
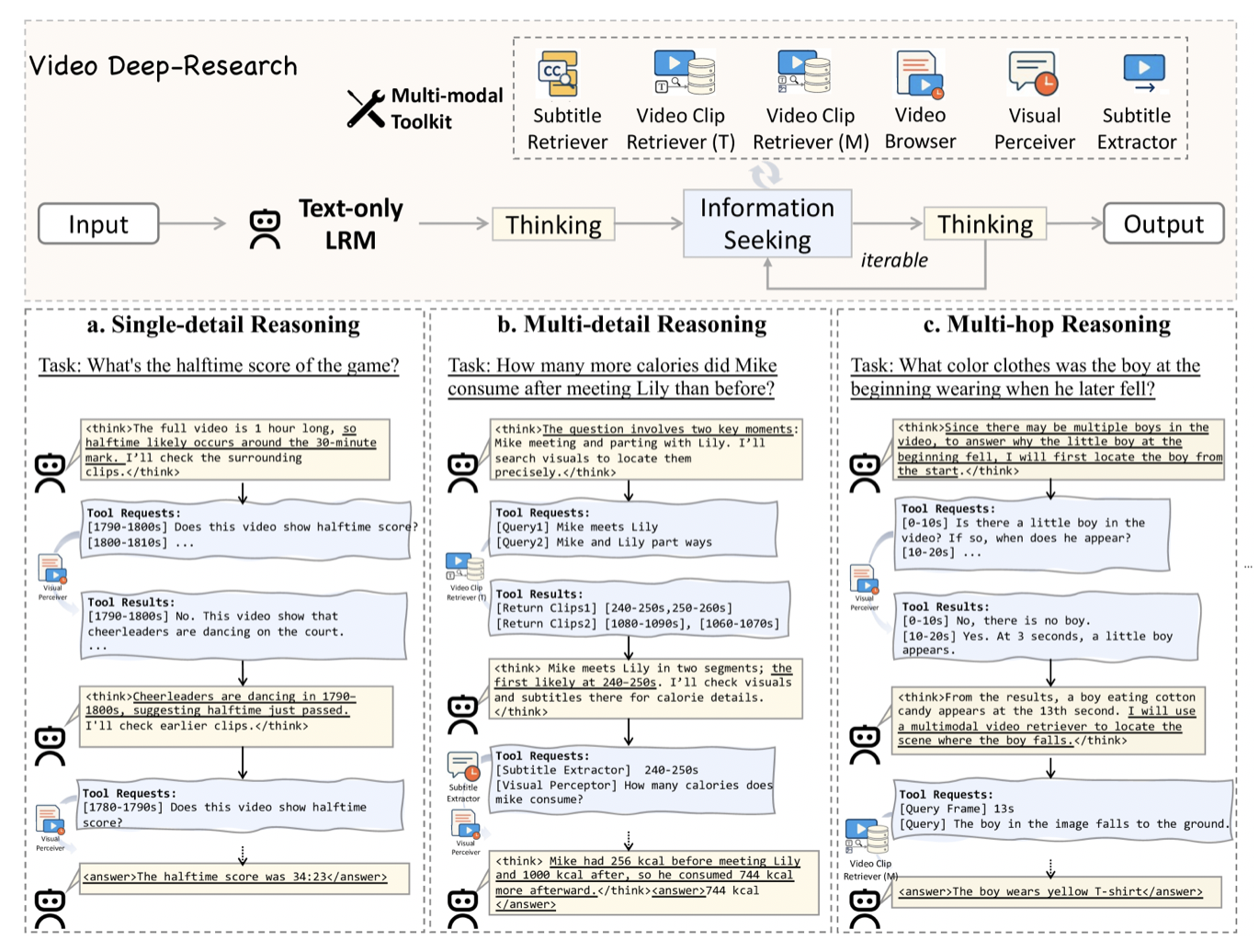
框架与推理机制
框架的核心是思维-行动循环机制。在每一步,LRM 基于当前上下文(包括原始查询、历史工具调用及结果)生成下一个决策。决策可以是两种类型:thought 表示继续分析或规划,action 表示调用工具并指定参数。当模型认为已有足够信息时,直接生成最终答案并终止循环。这种机制使模型能够自适应地控制信息获取深度,避免过度或不足的工具调用。
关键设计在于上下文的累积式更新。每次工具调用后,其输出文本结果被追加到对话历史中,形成新的上下文。例如,调用 Video Clip Retriever 后,返回的片段描述、时间戳和视觉摘要被自然语言化后加入上下文,使 LRM 能够像人类一样「阅读」和「思考」这些信息。这种文本化表示确保了 LRM 无需修改即可与多模态工具交互,保持了推理模型的纯净性。
Video Clip Retriever
Video Clip Retriever 用于检索与查询最相关的视频片段,其定义为:
𝒱ret = ℛv(q ∣ 𝒞v)
其中 q 是用户查询,𝒞v 是视频片段集合。实现上,视频被预分割为 10 秒非重叠片段,每个片段用 LanguageBind-large (428M) 编码为向量。检索时,查询也被编码为同空间向量,通过余弦相似度返回 Top-K 片段。检索结果包含片段的时间戳范围和视觉摘要描述,为后续推理提供精确的定位信息。
该工具的核心优势在于语义匹配而非时间遍历。当问题涉及特定场景、物体或动作时(如「视频中有人摔倒吗?」),检索器能够直接定位相关片段,避免模型需要扫描整个视频。这种方法特别适合「视觉中心」的查询,即答案可以从静态帧或短序列中推断的问题。
Subtitle Retriever
Subtitle Retriever 基于字幕内容检索相关片段,其定义为:
𝒮ret = ℛs(q|𝒞s)
其中 𝒞s 是字幕集合。与 Video Clip Retriever 的区别在于检索空间:前者在视觉空间检索,后者在文本空间检索。实现上,字幕也被分割为与视频对齐的文本片段,使用文本编码器(如 BERT)进行语义检索。返回结果包含字幕内容及其对应的时间戳范围。
该工具特别适用于「音频中心查询」,即问题需要依赖对话、旁白或字幕内容。例如,当问题是「车里那个人说了什么?」或「视频开头提到了哪些城市?」时,纯视觉检索难以定位,而字幕检索可以直接匹配关键词或语义。通过将视觉检索与字幕检索结合,框架能够覆盖更广泛的查询类型。
Visual Perceiver
Visual Perceiver 是 LRM 的「眼睛」,负责对指定时间范围的视频进行局部理解,其定义为:
TA = 𝒫c(q ∣ C[t0, t1])
其中 C[t0, t1] 是时间区间 [t0, t1] 的视频片段,TA 是返回的文本描述。实现上,使用 Qwen2.5VL-7B 或 Seed1.5VL-pro 作为视觉模型,从片段中采样最多 32 帧进行编码。模型生成针对查询的描述性文本,而非直接回答问题,保持了信息获取与回答生成的解耦。
关键设计在于帧数限制。相比于 GPT-4o 等商用 API 需要处理 384 帧,Visual Perceiver 仅用 32 帧即可生成高质量描述。这大幅降低了计算成本,同时通过前序检索器的精确定位,32 帧已足够覆盖相关语义。实验表明,在正确的时间范围内,32 帧与 384 帧的描述质量差异很小,但计算成本降低了一个数量级。
Subtitle Extractor
Subtitle Extractor 基于显式时间戳提取字幕内容,其定义为:
𝒮t = ℰs([t0, t1]|𝒞s)
该工具与 Subtitle Retriever 的区别在于检索方式:后者基于语义匹配,前者基于精确时间范围。当查询包含明确的时间参考时(如「视频中 1 分钟到 2 分钟发生了什么?」),直接提取比语义检索更高效。返回结果是该时间范围内所有字幕文本的拼接,为 LRM 提供连续的上下文信息。
实际应用中,该工具通常与其他工具组合使用。例如,LRM 可能先通过 Video Clip Retriever 定位相关片段,再调用 Subtitle Extractor 获取对应的字幕信息,最后整合视觉和文本描述生成答案。这种组合体现了 Agent 框架的灵活性:工具可以串行或并行调用,形成复杂的信息获取流程。
Video Browser
Video Browser 用于全局快速浏览理解,不依赖具体时间范围,其定义为:
TA = 𝒫b(q)
实现上,浏览器从视频中均匀采样固定数量的帧(如 32 帧),生成对视频整体主题、流程或结构的描述。该工具适用于「高层级问题」,如「这个视频的主题是什么?」「视频的整体流程是怎样的?」等需要全局视角的查询。与逐帧或逐片段扫描相比,全局采样提供了高效的概览能力。
浏览器的核心价值在于提供「上下文锚点」。在长视频理解中,模型需要先建立对视频的整体认知,才能理解具体片段的语义重要性。Video Browser 在早期阶段调用,为后续的检索和感知提供高层语义指导,使工具调用序列更加智能和高效。
🎯 训练细节与实验结果
实现细节
VideoDeepResearch 的实现采用模块化设计,各组件可独立选择和替换。大推理模型(LRM)使用 DeepSeek-r1-0528,这是一个纯文本模型,无需多模态训练。视觉感知器可选择 Qwen2.5VL-7B 或 Seed1.5VL-pro,前者是通用 MLLM,后者在视频任务上经过专门优化。检索器使用 LanguageBind-large (428M),这是一个轻量级的多模态编码器,在检索精度和效率间取得平衡。
视频预处理采用固定策略:将视频分割为 10 秒非重叠片段,每个片段独立编码为向量存储。对于无字幕视频,可以使用自动语音识别(ASR)生成字幕,或仅依赖视觉检索。工具调用的最大步数设为 10,防止模型陷入无限循环。每次 Visual Perceiver 调用最多处理 32 帧,Video Browser 同样采样 32 帧进行全局浏览。
主要实验结果
评估基准涵盖多个长视频理解数据集,包括 MLVU(Multimodal Long Video Understanding)、LVBench(Long Video Benchmark)、LongVideoBench 和 VideoMME-L。MLVU 是一个综合性基准,包含 NeedleQA、Action Count、Action Order、EgoQA、SportsQA、TutorialQA 等多种任务类型。
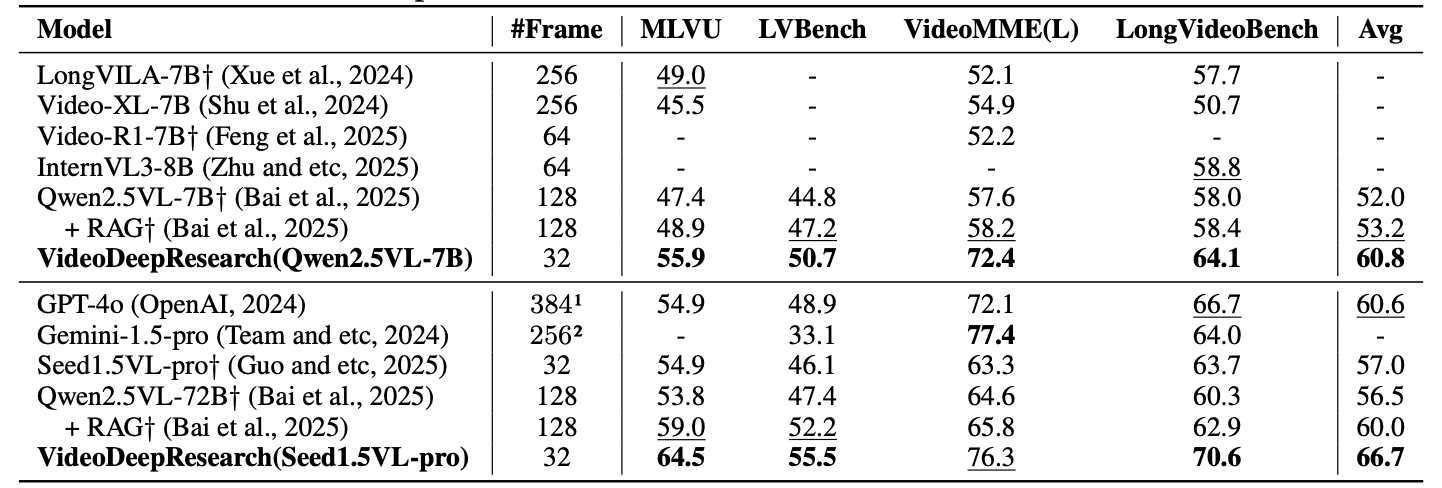
在 MLVU 测试集上,VideoDeepResearch (Qwen2.5VL-7B) 达到 55.9 分,显著超越 LongVILA-7B (49.0) 和 Video-XL-7B (45.5)。使用 Seed1.5VL-pro 作为视觉感知器时,分数提升至 64.5。在 VideoMML-L 上,Qwen2.5VL-7B 版本达到 72.4 分,远超 LongVILA-7B (52.1)。三个基准的平均分分别为 60.8 (Qwen2.5VL-7B) 和 66.7 (Seed1.5VL-pro),均超越 GPT-4o (60.6) 和 Qwen2.5VL-72B (56.5)。
在 LVBench 上,VideoDeepResearch 达到 50.7 (Qwen2.5VL-7B) 和 55.5 (Seed1.5VL-pro)。任务级分析显示,模型在 NeedleQA、Action Count、Action Order、TutorialQA 等任务上表现优异,这些任务需要精确的时序推理或计数能力。在 EgoQA 和 SportsQA 上表现相对较弱,原因在于检索模块难以准确定位相关片段,这两类任务的视频通常缺乏清晰的视觉边界或语义关键词。
效率分析
效率优势是 VideoDeepResearch 的核心贡献之一。在帧数消耗上,框架仅使用 32 帧进行视觉理解,而 GPT-4o 等商用 API 通常需要 384 帧。这意味着计算成本降低超过一个数量级,同时保持了相当的准确性。关键原因在于检索器的精确定位能力:通过先识别相关时间范围,视觉模型只需处理真正有用的信息。
Token 效率同样显著。由于采用文本化描述而非原始像素或密集 token,上下文窗口的使用更加高效。实验表明,与直接将视频编码为 token 的方法相比,VideoDeepResearch 的 Token 使用量减少 25.0%-17.4%。这对于长视频特别重要,因为传统方法的 Token 消耗随视频长度线性增长,而框架的 Token 消耗主要由查询复杂度和工具调用次数决定。
长视频鲁棒性是另一个关键指标。随着视频长度增加,端到端方法的性能下降通常在 10%-20% 范围内。VideoDeepResearch 的性能下降仅 4.9%,显著优于 GPT-4o 的 13.2%。原因在于检索和采样策略不依赖于视频长度:无论视频多长,检索器总是返回最相关的 K 个片段,Visual Perceiver 总是处理固定数量的帧。
消融研究
消融实验验证了各工具的必要性。移除 Video Clip Retriever 后,MLVU 分数下降 12.3%,表明视觉检索对定位相关片段至关重要。移除 Subtitle Retriever 后,依赖对话的任务(如 EgoQA)下降 8.7%,验证了文本检索对音频中心查询的价值。移除 Video Browser 后,高层级问题(如「视频主题」)准确率下降 10.2%,说明全局浏览提供必要的上下文锚点。
工具调用顺序分析显示,最优策略通常是:先调用 Video Browser 建立全局认知,再根据查询类型选择 Video Clip Retriever 或 Subtitle Retriever,最后调用 Visual Perceiver 生成详细描述。这种顺序与人类的视频理解过程一致:先概览,再定位,最后深入分析。
💡 洞察与结论
Agent 框架的有效性方面,VideoDeepResearch 挑战了「只有大规模 MLLM 才能解决长视频理解」的假设。实验表明,一个纯文本推理模型配合工具包,可以超越专用的多模态大模型。核心原因在于智能编排比暴力扩展更有效:通过让模型自主决定「何时获取什么信息」,避免了无效的帧扫描和冗余的计算。这与人类的认知过程一致:我们不会逐帧观看视频,而是通过扫描、定位、聚焦的策略提取关键信息。
模块化设计的价值体现在多个维度。首先,可替换性:LRM、视觉感知器、检索器可以独立升级。例如,将 Qwen2.5VL 替换为更强的视觉模型,直接提升整体性能,无需重新训练整个系统。其次,效率:模块只处理相关片段,避免了全视频编码的计算浪费。最后,可扩展性:框架可以集成检索增强学习(RL)、测试时缩放(test-time scaling)等优化策略,每个策略可以在特定模块上应用,而非影响整个系统。
实际部署意义在于资源受限环境的友好性。许多场景无法部署或频繁调用 GPT-4o 等商用 API,而 VideoDeepResearch 可以使用开源组件在本地运行。成本效益分析表明,在相同硬件预算下,框架可以处理更长的视频或更多的并发请求。此外,模块化设计降低了集成门槛:开发者可以复用现有组件,而非从零构建端到端系统。
局限性与未来方向值得关注。首先,某些任务类型(如 EgoQA、SportsQA)的检索定位困难,表明检索器的语义理解能力有待提升。未来可以引入多级检索或时序感知编码器,提高对动态场景的定位精度。其次,框架依赖预分割策略,10 秒片段可能切断重要事件,需要更自适应的分割算法。最后,工具调用的决策过程目前是隐式的,未来可以引入可解释性机制,分析模型的决策逻辑。
理论启示方面,VideoDeepResearch 提供了一个「组合优于扩展」的成功案例。在大模型时代,我们倾向于追求更大的模型和更长的上下文,但这可能不是最优解。该研究表明,通过仔细设计接口和交互,较小模型的组合可以在特定任务上超越更大的单一模型。这一思路不仅适用于视频理解,也适用于其他需要处理长序列或复杂推理的任务。